
この記事は「データベーススペシャリスト資格に興味はあるが、どのようなものか?どう学ぶのか?」という方向けに、具体的な内容と私自身の挑戦ログをお伝えする。学び中の方や、これから学ぼうとされる方の参考になれば幸いだ。
今回はSQLによるテーブルの結合(1/3)について書く。
※注意点として、SQLはDBMSによって作法が異なる。この記事はGoogle Big Queryに準拠するものであることをお含みおき願いたい。
なぜ、テーブルは複数あるのか
前回のおさらい
- 分析とは「分類し比較する」ことで、SQLではグループ化と集計関数を用いる。前回までで「group byと基本的な集計関数(sum,avg,max,min)」および「集計結果の絞り込み(havig)と柔軟なグループ化(if,case)」を学んだ。
- ここまでの学びにより、例えば「webログを用いたユーザーごと訪問回数の調査」や統計学的な使い方も学べた。すなわちあるグループごとの該当する数を取得した結果をSQLで求め、BIツールに読み込んでヒストグラムにするなど。
- ただし、今まではあくまで一つのテーブルに対する列・行・グループ化の操作だった。今回から複数テーブルの操作を学んでいく。
テーブルとは(おさらい)
- テーブルは集合であり関数。意味のあるデータのまとまりであり、ある入力に対し一意の結果が求まる。
- この原則に基づき、テーブルを扱いやすいように切っていく(いつでも戻せるように)のが正規化。
- 単一のごった煮テーブルで管理すると、更新のとき非常に扱いづらい。
- このあたりは4月29日一次まとめにて整理済。
複数のテーブルがある意味
- 複数のテーブルにわける原則は前述のとおり。もう少し実務的に言うと「複数のテーブルがある意味は、単一のテーブルで扱うよりメリットがある」から。
- メリット①、異なる性質のデータを扱いやすい。実務は通常、見積⇒発注⇒納品⇒支払のように一連の業務フローからなり、それぞれ手順も、担当者も、扱うデータも異なる。よってそれぞれの業務工程ごとにテーブルも分けたほうが管理が簡単で良い(必要な要素が小さなひとまとまりになってるイメージ)。ただし、後から必要に応じて統合できるよう、外部キーなどを用いて関係を整理する必要はある。
- メリット②、一定期間ごとに集計されたデータを扱いやすい。例えばGoogleアナリティクスのデータは自動的に日別のテーブルが作成される。これは、24時間365日レコードを取得するので、きりの良い所で区切らないとテーブルが巨大で扱いづらくなるから。
分析では複数テーブルをつなげる
- そして、分析においては複数のテーブルをつなげる必要がある。なぜなら、筋の良い論点を導くためには、より多様で幅広い(たくさんの切り口・列を持つ)、より大量で長期間の(たくさんのレコード・行を持つ)データを扱う必要があるから。
- なお、メリット①で「異なる性質(列)で分けたデータ」を、“横”につなげる操作を「結合(join)」と言う。”横”と表現したのは、表で見ると横に列が追加されていくイメージだから。
- メリット②で「一定期間ごとに集計されたデータ」を、“縦”につなげる操作を「集合演算(union)」と言う。”縦”と表現したのは、表で見ると縦に行が追加されていくイメージだから。
テーブルの結合(基本)
もっとも基本のパターン
- まずは「異なる性質(列)で分けたデータ」を、”横”につなげる操作「結合(join)」について
- もっとも基本のパターンは「2つのテーブルの値が重なっているレコードを残して結合」する「内部結合(inner join)」。これは、今後の他のjoinの基本となるためぜひ覚えておきたい。
構文
- select フィールド名
- from テーブル名①
- inner join テーブル名②
- on テーブル名①.テーブル名①の結合に使うフィールド名 = テーブル名②.テーブル名②の結合に使うフィールド名
事例
- サンプルとして「small_sales_1」という販売テーブルと、「small_master」という商品マスタテーブルを用意。それを結合するSQL例。
- ポイントとして「inner joinのinnerは省略可能」「asによる別名付与は便利。テーブルを短い名前で表現できるため」「SQL1行目のselectにおけるproduct_idの前にhanbai.とつけている。joinで2つのテーブルに共通の列名を指定するときはテーブル名も必須。なぜならどちらのテーブルの列なのか示す必要があるから」

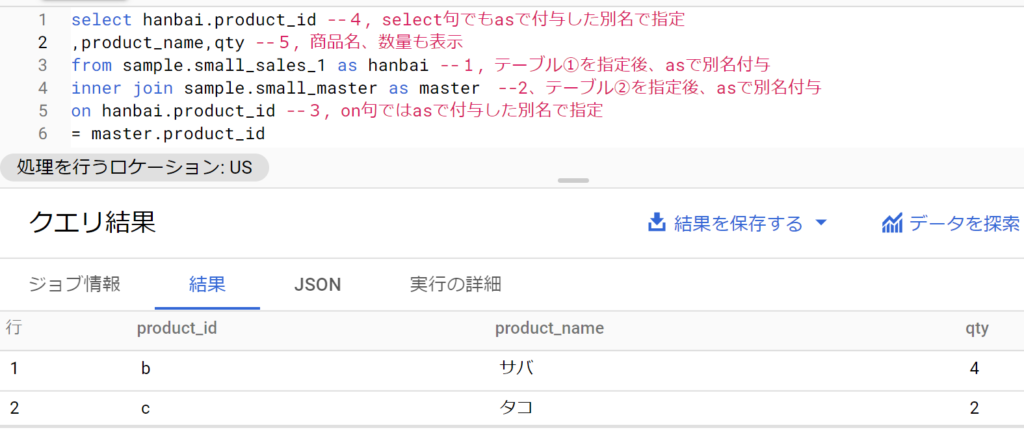
using句の利用
- joinにおいて結合する列名が同じ場合、usingでシンプルに代用可。
- その場合、on以降を「using(列名)」と記述する。
テーブルの結合(その他)
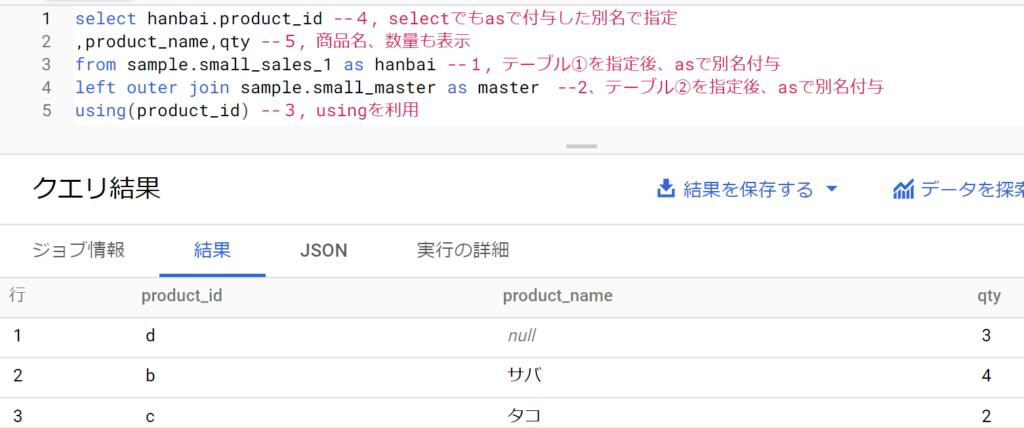
先に指定したテーブルの値を残す(left outer join)
- fromで先に読み込むテーブルを「左側」と解釈し、これは全て活かしたうえで、left outer joinとして指定するテーブルを結合するやり方。
- 構文は「inner join」部分を「left outer join」に置き換えるのみ。
- 事例は以下のとおり。inner joinと異なるのは、product_idがdの売り上げも記載される点。これは先に指定したsmall_sales_1が活かされるため。
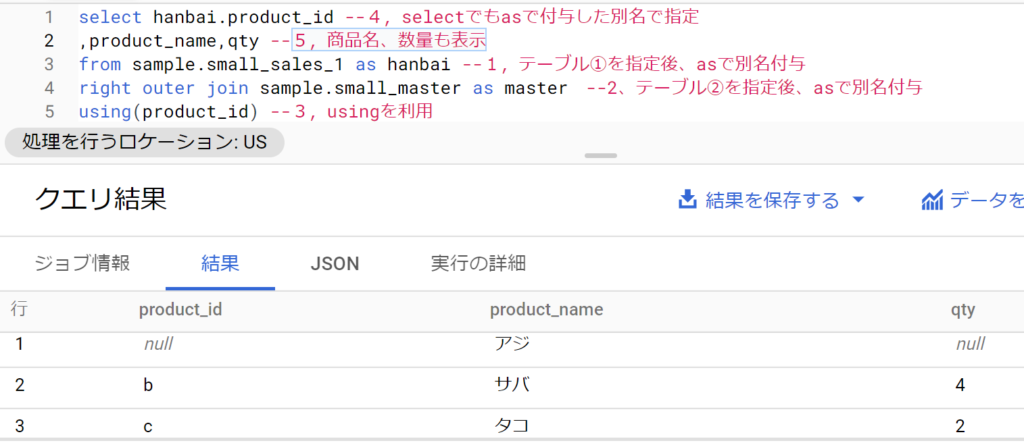
後に指定したテーブルの値を残す(right outer join)
- right outer joinとして後から指定するテーブルを「右側」と解釈し、これは全て活かし結合するやり方。
- 構文は「inner join」部分を「right outer join」に置き換えるのみ。
- 事例は以下のとおり。inner joinと異なるのは、product_idがaのマスター情報も記載される点。これは後に指定したsmall_masterが活かされるため。
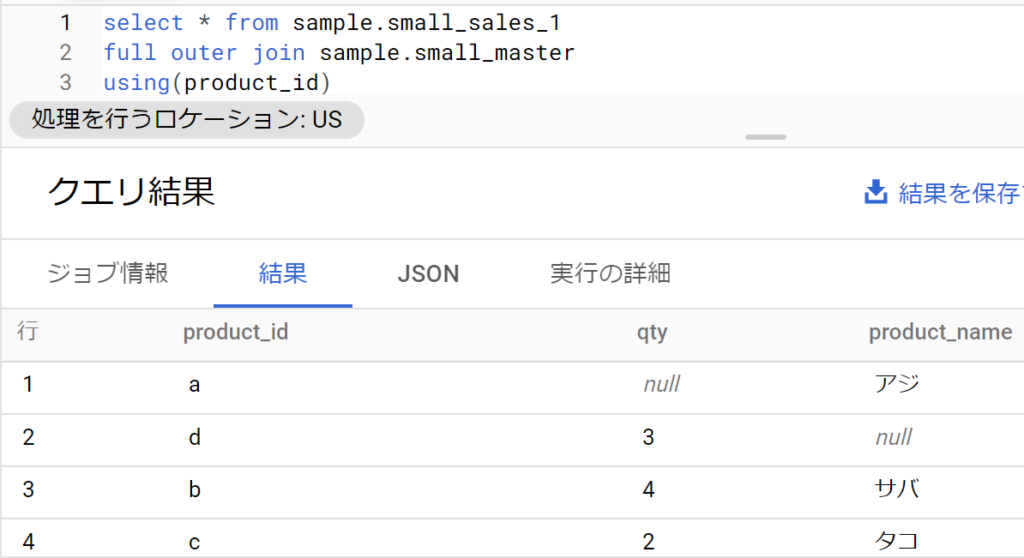
2つのテーブルの全レコードを残す(full outer join)
- fromで先に指定するテーブルを「左側」、full outer joinとして後から指定するテーブルを「右側」と解釈し、両方を全て活かし結合するやり方。
- 構文および事例は以下のとおりでかなりシンプルに書ける。inner joinと異なるのは、product_idがdの販売情報も、aのマスター情報も記載される点。これは両方のテーブル情報が活かされるため。
考察
- 今までは単一テーブルの操作を学習。今回から複数テーブルの操作を学んでいる。
- これは、実務では「扱いやすさ」の観点から複数テーブルに分かれているが、分析においては「幅広く見る」ためにテーブルをつなげる必要があるから。
- ようやくここで、データベーススペシャリスト資格の優先学習ポイントである「①論理設計(業務で扱うデータを整理し、ER図で書く)」と「②SQL」が意味を持って紐づいてきた。
参考書籍
- 集中演習 SQL入門/木田和廣/株式会社インプレス
- データベーススペシャリスト2022年版/三好康之/翔泳社
- おうちで学べるデータベースのきほん/ミック,木村明治/翔泳社

コメント