
この記事は「データベーススペシャリスト資格に興味はあるが、どのようなものか?どう学ぶのか?」という方向けに、具体的な内容と私自身の挑戦ログをお伝えする。学び中の方や、これから学ぼうとされる方の参考になれば幸いだ。
今回はSQLのグループ化と集計(後半)について書く。
※注意点として、SQLはDBMSによって作法が異なる。この記事はGoogle Big Queryに準拠するものであることをお含みおき願いたい。
集計結果の絞り込み
前回のおさらい
- SQLについて、今まではフィールド(列)やレコード(行)の操作など「データを扱う基礎」を学んできた。今回から「分析の基本」を順に学ぶ。分析とは「分類し比較する」ことで、SQLではグループ化と集計関数を用いる。
- 前回はgroup byと基本的な集計関数(sum,avg,max,min)を学んだ。
集計結果の絞り込み
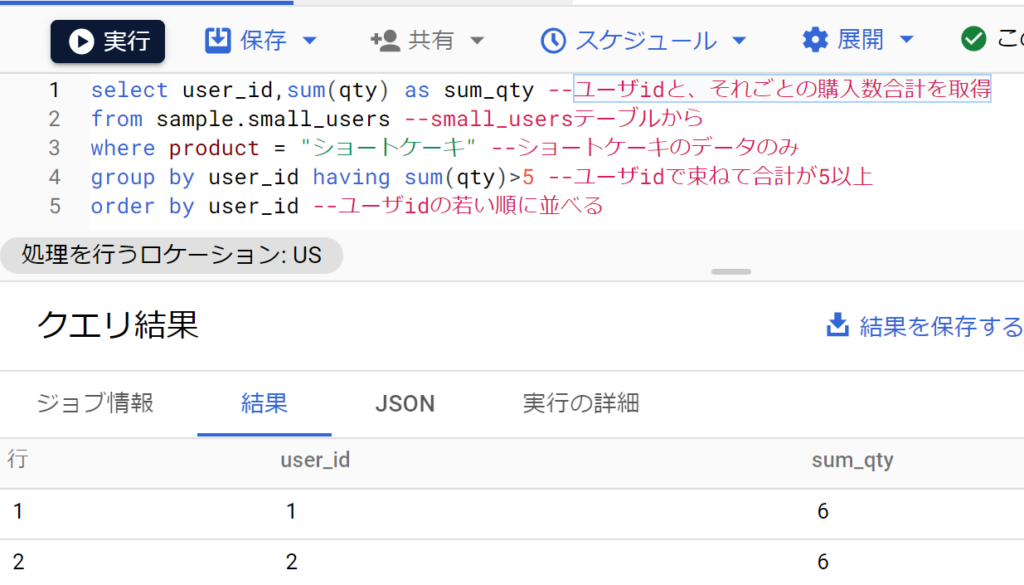
- 集計結果の条件で絞り込みしたいときは「having」を使う。直訳すると「~を持つ」。例えば「値が○以上」など。
- 以下は、まず商品がショートケーキのレコードに絞ったうえで、さらに合計値が5以上のレコードを抜き出すもの。from、whereのあとにgroup by、havingと続き、最後にorder by、limitと記述する順番に注意。(SQLの内部処理も概ねこの順番)
柔軟なグループ化
任意の分類でグループ化する(if)
- 今までのgroup byは値そのもの(user_idなど)で束ねていた。
- 任意の分類でグループ化するときは「if」と「case」。
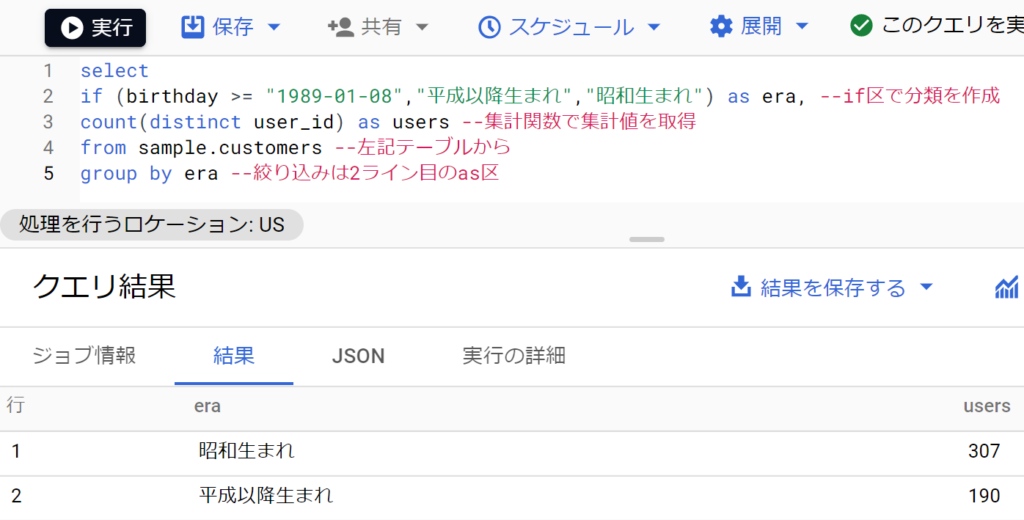
- ifの構文は「if(条件式,trueの場合の値,falseの場合の値)」
- 例えば以下は「平成以降生まれ」と「昭和以前生まれ」でグループ化する例
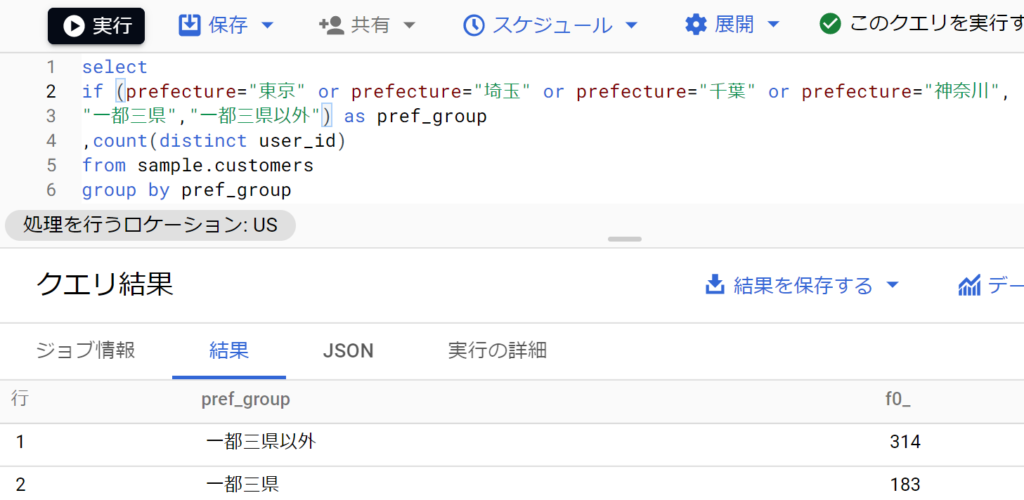
- ifの条件式にはandとorも利用可。例えば以下は[prefecture]フィールドを対象とした条件式をorでつなげることで、「東京」「神奈川」「千葉」「埼玉」のいずれかに合致するなら「一都三県」、それ以外に合致するなら「一都三県以外」にグループ化するように指定している。
- orが増えたときはin演算子を使っても良い。if((prefecture in(“東京”,”神奈川”,”千葉”,”埼玉”)is true,”一都三県”,”一都三県以外”)と記述する。
- また、is null関数とあわせて「未登録」「登録済」などでも分類可能。
任意の分類でグループ化する(case)
- caseの構文は以下。
- case
- when 条件式 then 該当した場合の値
- when 条件式 then 該当した場合の値
- else いずれにも該当しない場合の値
- end
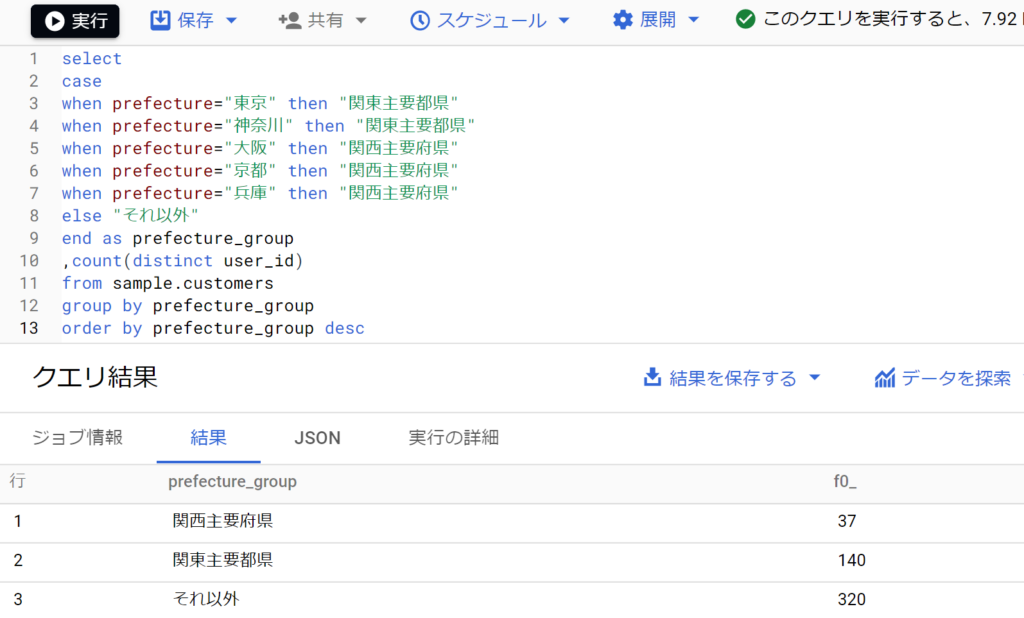
- 利用例として、[prefecture]フィールドの値が[東京][神奈川]であれば「関東主要都県」、[大阪][京都][兵庫]であれば「関西主要府県」、それ以外の都道府県であれば「それ以外」と3つのグループに分類するケースは以下。
- whenに続く条件式は「古い順、または新しい順で記述」と覚えておく(順序が変だと、グループ化がおかしくなるため)
復習
問題006
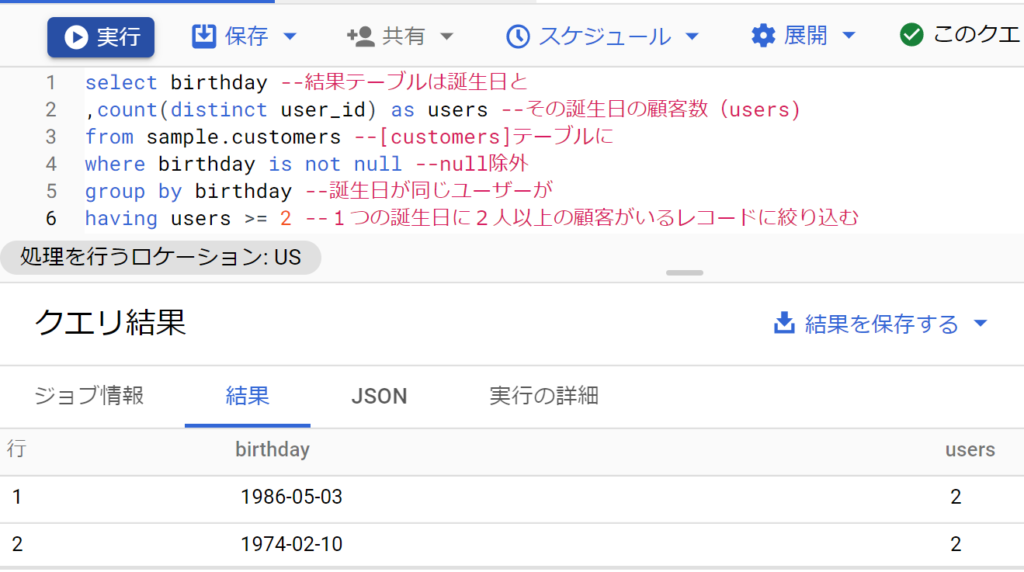
- [customers]テーブルに誕生日が同じユーザーが何人いるか調べてください。結果テーブルは誕生日(birthday)とその誕生日の顧客数(users)の2カラムとし、1つの誕生日に2人以上の顧客がいるレコードに絞り込んで表示してください。
- 誕生日で束ねたうえで、ユーザ数をuser_idでカウントする。先にcountおよびas usersが処理されるため、havingでusersを条件式に使えることに注目したい。なお、そのままだとnullも入ってくるのでwhereでレコードを除外している。
問題007
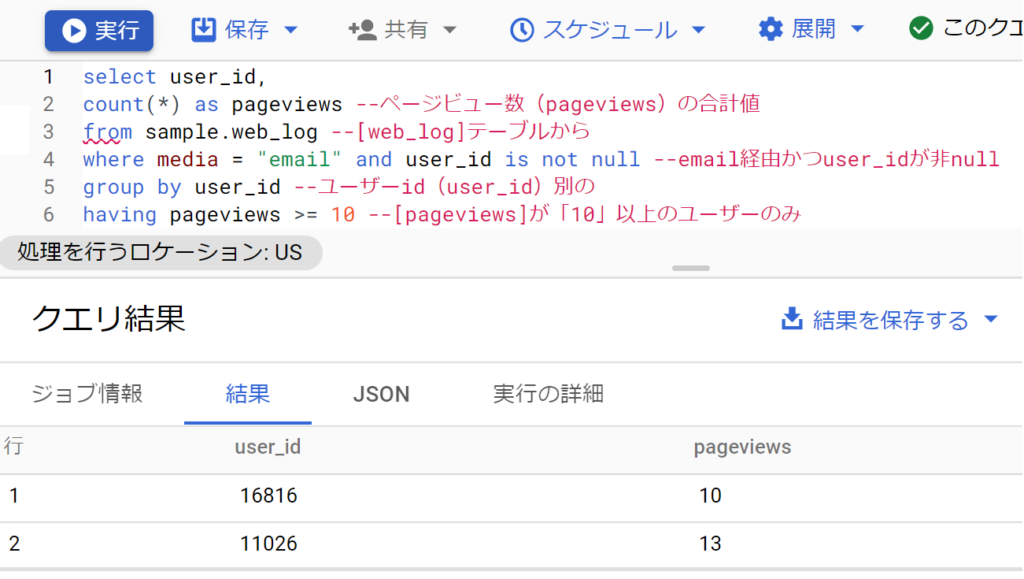
- [web_log]テーブルから、ユーザーid(user_id)別のページビュー数(pageviews)の合計値を取得してください。ただし、そのページビューはemail経由で発生したものだけとします。結果テーブルは[user_id]と[pageviews]の2カラムとし、[pageviews]が「10」以上のユーザーのみを含めます。[user_id]が「null」のレコードは除外してください。[web_log]テーブルは、1レコードが1つの[page_view」で構成されています。
- user_idで束ねたうえで、データ数をでカウントする(1レコードが1つのpage_viewで構成されるので)。whereでemail経由と非nullを絞り込む。pageviewsが10以上は集計値を用いた条件式なのでhavingで絞り込む。
問題008
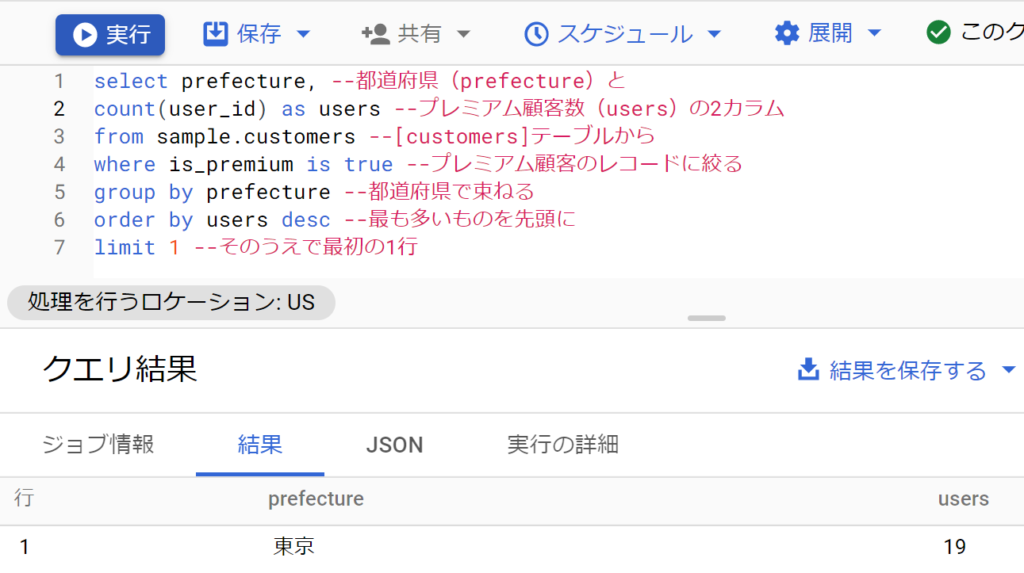
- [customers]テーブルから、プレミアム顧客がもっとも多い都道府県とプレミアム顧客数を求めてください。結果テーブルは、都道府県(prefecture)とプレミアム顧客数(users)の2カラムとします。
- 都道府県で束ねたうえで、プレミアム顧客のmaxを取り、降順にならべ、最初の1行を取る。
問題009
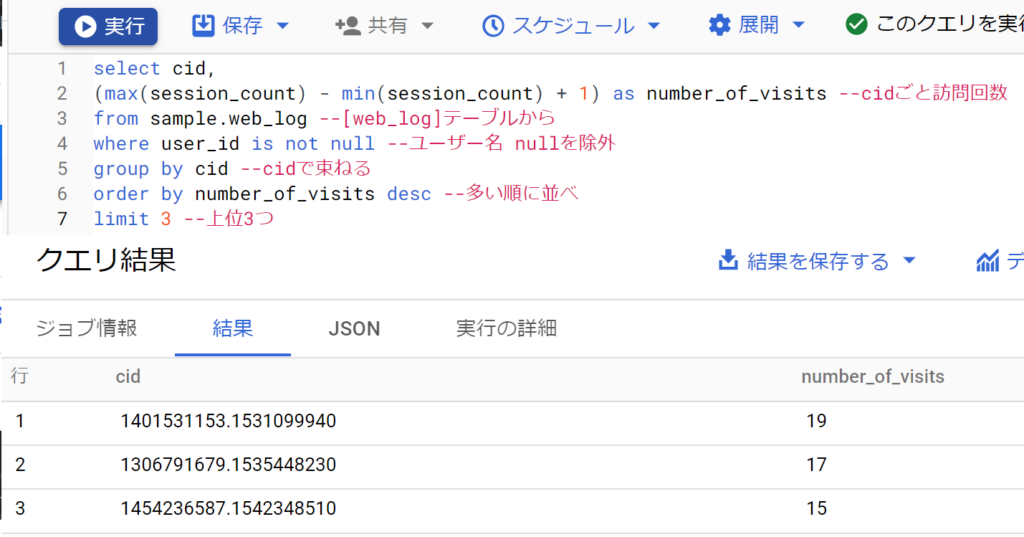
- 問題文。[web_log]テーブルからユーザー別の訪問回数(number_of_visits)を取得してください。結果テーブルは[cid]と[number_of_visits]の2カラムとし、訪問回数が多い順に3ユーザーに絞り込んで表示します。
- 補足。[web_log]テーブルにはcid(webブラウザ識別id)、user_id(顧客識別id)、page(閲覧されたwebページ)、session_count(訪問回数)などのカラムがあるのでこれを解説する。
- まず、cidとはクライアントID(CID)のこと。個々のブラウザの閲覧を紐づけるためのIDで、各ブラウザのCookieの中に格納されている。[web_log]テーブルではcidが個別ユーザ(user_id)と紐づいている。
- 次に、pageはホームページ内の特定ページのこと。レコードは1PV(ページビュー。特定ページを見ること)ごとに作成される。例えばあるユーザが3ページ見た場合、3PVなので3レコードが作成される。
- 次に、session_countはセッションのこと。例えば1回ホームページに訪問し、10個のページを閲覧した場合はセッションは1,PVは10になる。よって、このアクションにより[web_log]が10レコード生成されてもsession_countは変動しない。session_countは再度このホームページに訪問した場合いおいて、カウントアップしていくもの。
- 最後に、今回の設問は「ユーザー別の訪問回数」である。[web_log]レコードの取得期間中(date_timeが”2017-01-06″から”2019-12-27″の間)に、session_countを多い順で並べるとユーザ”14020″さんの”21″回がヒットする。なお、このユーザーの最小session_countは”3″。よってこのユーザーの(ログ取得期間中の)訪問回数は「21-3+1=19回」となる。
問題010
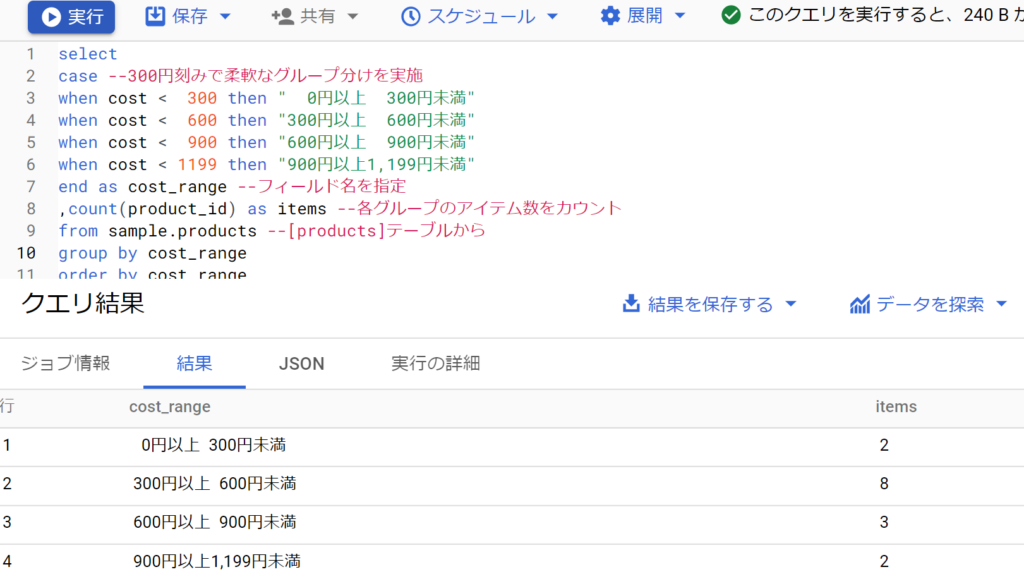
- 問題文。[products]テーブルから、仕入金額(cost)ごとの商品アイテム数を取得してください。仕入金額は「0円以上300円未満」「300円以上600円未満」…と300円刻みで「900円以上1,199円未満」までを分類して[cost_range]とし、アイテム数は[items]とします。並び替えは[cost_range]の小さい順としてください。
- 補足。「case」構文を使用して柔軟なグループ化を実施。この例をもって、SQLが統計学的な使い方をできることがわかる。すなわちあるグループ(階級)ごとの該当する数(度数)を取得した結果(度数分布表)が求められるし、それをBIツールに読み込んで棒状のグラフにしたもの(ヒストグラム)にすることも可能である。
- テーブルが大きくてもBig Queryは処理が速いので、大量データ処理はBig QueryとSQLで行い、視覚化はtableauなどのBIツールで、と使い分けると分析者としての引き出しが広がる。
考察
- SQLについて、分析とは「分類し比較する」ことで、SQLではグループ化と集計関数を用いる。前回はgroup byと基本的な集計関数(sum,avg,max,min)を学び、今回は集計結果の絞り込み(havig)と柔軟なグループ化(if,case)を学んだ。
- 学びの活用。ここまでの学びにより、例えば「webログを用いて、特定期間中のユーザーごと訪問回数を調べ、上位3ユーザを抽出」して「そのユーザの訪問日時・利用デバイスを分析」などできるようになった。(一部は記事内の問題009で実践)
- また、統計学的な使い方も学べた。すなわちあるグループ(階級)ごとの該当する数(度数)を取得した結果(度数分布表)をSQLで求めるということ。また、それをBIツールに読み込んで棒状のグラフ(ヒストグラム)にすることも可能。
参考書籍
- 集中演習 SQL入門/木田和廣/株式会社インプレス
- データベーススペシャリスト2022年版/三好康之/翔泳社
- おうちで学べるデータベースのきほん/ミック,木村明治/翔泳社

コメント