
この記事は「データベーススペシャリスト資格に興味はあるが、どのようなものか?どう学ぶのか?」という方向けに、具体的な内容と私自身の挑戦ログをお伝えする。学び中の方や、これから学ぼうとされる方の参考になれば幸いだ。
今回は分析の基本と、SQLのグループ化と集計(前半)について書く。
分析の基本
前回おさらい
- SQLの基本かつ王道の命令「select from」について、5月3日は「フィールド(表テーブルにおける列単位のデータ)の操作」を試した。具体的にはフィールドの参照・並び替えや、フィールドの作成・計算・別名付与など。
- また、5月4日は「レコード(表テーブルにおける行単位のデータ)の絞り込み操作」を試した。具体的にはlimit(○行まで),where(条件で絞り込み),その他条件(and,or,in,like,between)など。
- 「フィールド操作」「レコード操作」など今までは「データを扱う基礎」を学んだ。今回から「分析の基本」を順に学ぶ。
分析とは何か
- 分析とは、分類して比較すること。言い換えると「世の中にあるデータについて切り口を定め、その切り口で束ね、集計し、比べること」。
分析はどう役立つか
- 自分の人生・世の中をより良くするのに役立つ。なぜなら、問題解決のステップは「疑問⇒仮説⇒検証」であり、データ分析は「検証」において役に立つから。かつて統計が印刷物によって提供されていた時代は個人が検証するのはとても大変だったが、いまはとても簡単になった。(ただし、必要なデータがどこにあり、どう扱うかは学ぶ必要があるが)
問題解決のステップ
- 「疑問⇒仮説⇒検証」について具体的に。まず疑問を持つ。「なぜ、このようになっているのだろう?」。ここがすべての知的活動のはじまり。
- つぎに仮説を持つ。「もしかして、こういうことではないか?」。疑問を説明するためのものであり、誰かが言っていることでも、自分の経験に基づく考えでもよい。
- 最後に検証する。仮説の切り口をもとにデータを集計し、比べてみる。それにより仮説が正しそうだとわかれば、具体的な行動に移せる。
- 問題解決の第一歩は問題そのものの発見、つまり「気づき」。言い換えると「論点」。筋の良い論点を見つけられれば問題は解決したも同然、というのは問題解決の鉄則。
- しかし、筋の良い論点をすぐに見つけるのは難しく、経験と仮説検証の繰り返しが不可欠。つまり「論点のアテをつけてみて、検証してみて、正しそうだと分かったらその解決に取り組む」スタイル。検証はある意味「思いつき」を強固にし、解決に向けて進むための土台とも言える。
問題解決の事例1:犯罪率の削減
- 「最も多く犯罪率を削減させた市長」としてギネスブックにノミネートされているルドルフ・ジュリアーニ前ニューヨーク市長の場合。
- ジュリアーニ市長は「路上での強請(ゆすり。車が赤信号などで停まったとき、勝手に窓掃除など行い、運転主に金を払わせるもの)」を問題視した。とくに市の出入り口での犯罪は人の流れを止めてしまうからだ。しかし、強請は現行犯なので直接の排除は難しい。
- そこで「交通規則を無視した道路の横断」という軽犯罪を徹底的に取り締まった。結果として1カ月で強請は激減した。
- この場合、「どうしたら凶悪犯罪を減らせるだろう?(疑問)」⇒「小さな犯罪を取り締まれば(凶悪犯罪の予備軍を減らせるので)良いのでは?(仮説)」⇒「実際にやってみて、データをとり効果を見る(検証)」というサイクルを経ている。
問題解決の事例2:経済データ分析
- たとえば「なぜ日本の給料は上がらないのか?」と疑問を持つ。
- そして『「景気悪化⇒中小企業の人員削減⇒低賃金のまま大企業へ流入(大企業は景気悪化で先行き不明なので、内部留保を維持するため人件費を抑え利益確保に走る)⇒景気悪化…」という負のスパイラルが起きているのでは?』と仮説を立てる。
- そして『関連データ(法人企業統計調査)を「会社の規模」という切り口で束ね、人員・給与水準・人件費を集計し比較する』という検証を行う。
- もし仮説が正しそうだと分かったら、それを改善するための取り組みを考える。たとえば個人ですぐにできることは高成長産業(ITなど)関連の学びによる生産性向上などだ。
問題解決の事例3:ビジネスデータ分析
- たとえば「お金がかかる販売促進活動をどのようにすべきか?」と疑問を持つ。
- そして「広告にお金を使うか?」と仮説を持つ。
- そして「googleアナリティクスのメディアレポートを「ユーザー」という切り口で束ね、訪問経路・コンバージョン率・デバイスカテゴリ・日時等を集計し比較する」という検証を行う。
- 仮説と検証を繰り返すことで、より筋の良い打ち手を絞り込める。最初は「広告にお金を使う」だった仮説が、「大都市圏で、土日午後22時から深夜0時までに、スマホを利用したユーザを対象にcpcおよびコンバージョン率を上げるための施策を行う」のように具体的になっていく。
まとめ
- 自分や世の中の問題を解決するには、筋の良い論点(解決策)を見つける必要がある。筋の良い論点を見つけるには、「疑問・仮説・検証」のサイクルを回すことが不可欠。サイクルを回すにはデータ分析で「検証」する必要がある(疑問・仮説までだと、個人の思い込みに留まる)。
- ただ、仮説と検証は何度も回す必要があるので、つど他者に依頼すると時間がかかる。だから、データ分析のやり方を個人で学び、自分でやれるようにして、経験を蓄積して考えを広げていくことが重要だ。
- なお、私の場合はITコンサルにおいて「疑問と仮説」は経験と先人の教えでいくつか思い浮かべ、「検証」は現場へのヒアリングやエンジニアの方への分析に頼るスタイルだった。コンサルは対人間なのでヒアリングは必須だが「データに基づく分析を自分で回す」スキルは必須になりそうだ。頭でっかちにならず、地に足の着いた論点を見つけ、行動に移し、より良くしていくために。学びや分析はその手段であることを忘れずに。
SQLのグループ化
グループ化とは
- 分析とは分類して比較すること。言い換えると「世の中にあるデータについて切り口を定め、その切り口で束ね、集計し、比べること」。この分類・比較をSQLで行うのがグループ化。
- グループ化の基本的な考え方は2つ。「同じ値が入った複数のレコードをまとめて1行にすること」「そのうえで、量的なデータが格納されているフィールドについて合計や平均などの集計を比較できるよう取り出すこと」
- グループ化の重要なポイントは2つ。「どのフィールドを基準(切り口)としてグループ化するかで結果が変わる」「複数のフィールドを基準としてグループ化することもできる」
グループ化の構文
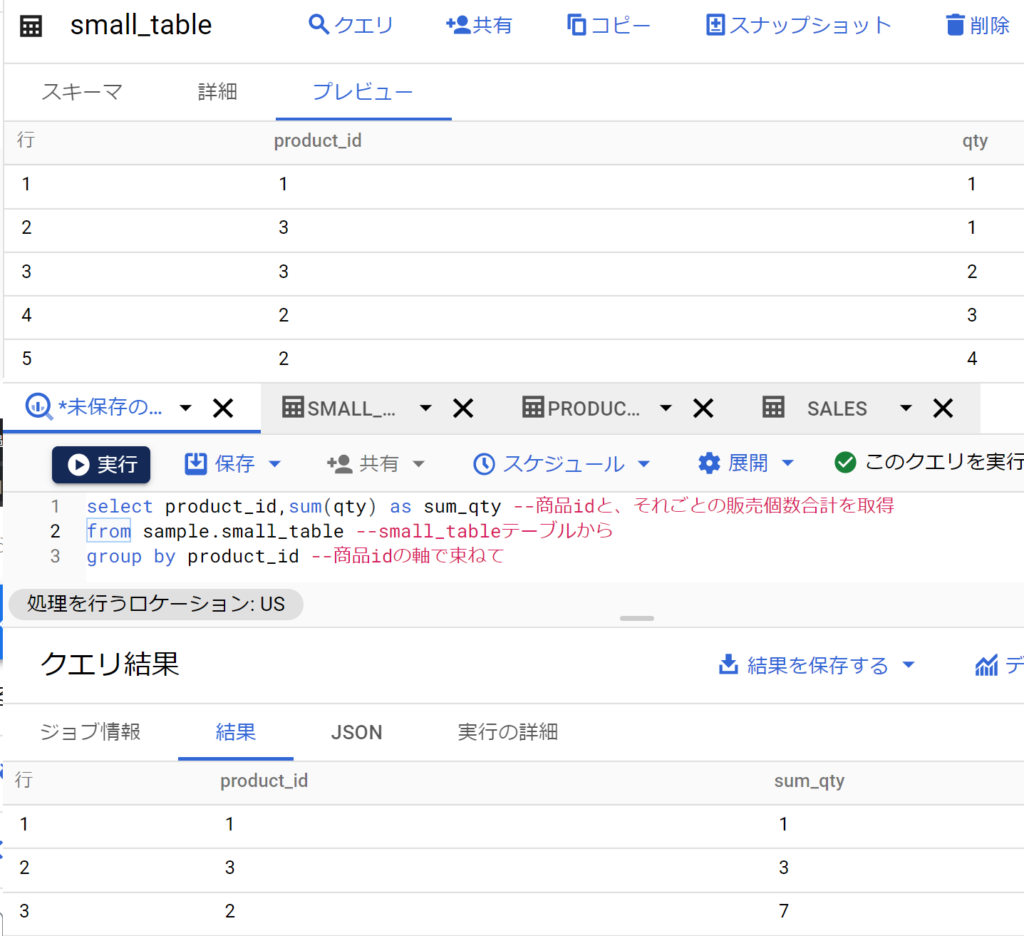
- グループ化をSQLで実現するのが「group by」。「select フィールド名,集計関数 from テーブル名 group by フィールド名」となる。
- group byとselectで指定するフィールド名は同一とするのが一般的。たとえば「商品」を切り口にデータを束ねた場合、分析表の最初の列は当然「商品」とするのが自然だから。
- 集計関数は、束ねたデータの合計等を表示するためのもの。
- 以下がもっとも基本的なgroup byの例。基本的な記述方法としてしっかり覚えておく。(イメージ図上段はサンプルで作った小さなテーブル。下段がSQLと処理結果)
SQLの集計関数
集計関数の種類
- グループ化に欠かせないのが集計関数。データを束ねたうえで、合計・平均など色々な切り口で集計・比較をおこなうため。
- 基本的な集計関数は「グループ内のレコード数を数えるcount(*)、グループ内の値の個数を数えるcount(フィールド名)、グループ内の固有な値の個数を数えるcount(distinct フィールド名)」、合計のsum、平均のavg、最大値のmax、最小値のmin」
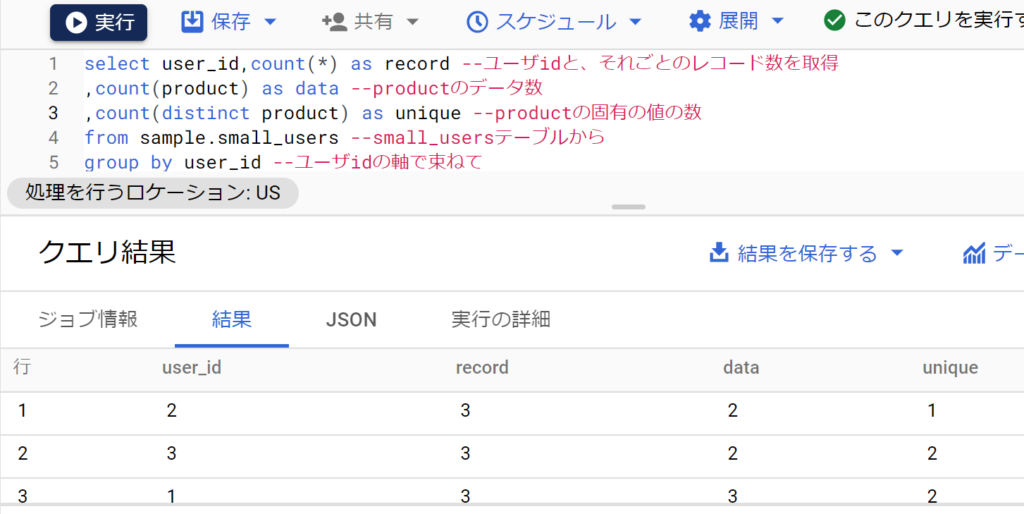
データの個数を数えるcount関数
- count関数はとても良く使う。レコード数、データ数、ユニークな値の数のどれを取るかで結果も意味も大きく変わるので注意。なおdistinctとは直訳すると「別個の」という意味。
- まず、count関数の基本パターンを試すためのサンプルテーブルを以下のとおり用意。

- 次に、以下のとおりcount関数の各パターンを試す。ユーザ1~3が各々3回買い物したので、レコード数は3。データ数はnullをカウントしないのでユーザ2,3は2になる。ユニークな値はユーザ1は2(クッキーとショートケーキ)、ユーザ2は1(ショートケーキ)、ユーザ3は2(ショートケーキとゼリー)となる。
- なお、Googleアナリティクス4はBig Queryにwebログがエクスポートされるので、GA4が一般的になるほどSQL活用の機会は増える。例えばユーザidごとにデータを束ね、webページのurlをデータ数でカウントすれば「ユーザごとページビュー数」が求まる。また、ユニークな値の数でカウントすれば「ユーザごと閲覧したページ種類数」が求まる。
合計、平均、最大、最小を取得する関数
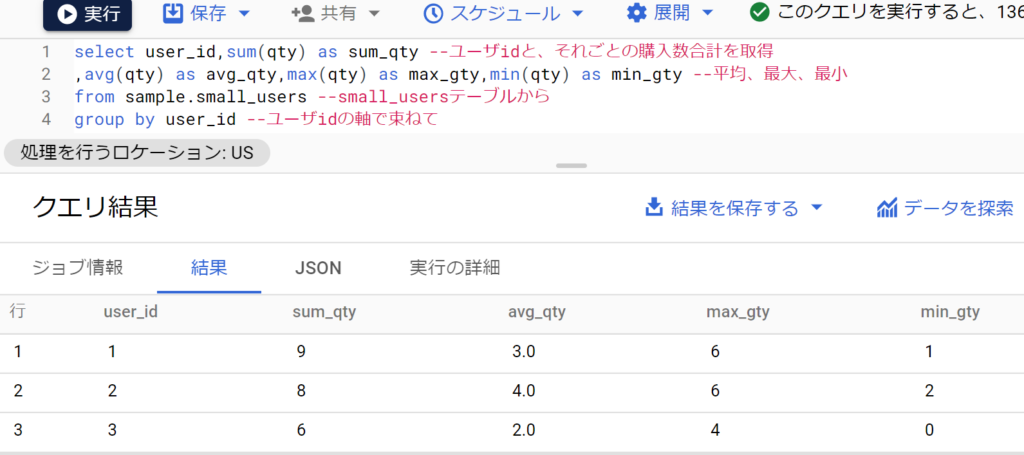
- 今後はユーザごとに各種集計値を取得してみる。
- まず、以下はテーブルの再掲。

- 次に、以下が集計値の結果。ユーザ1は合計9個買い、平均は9÷3=3、最大6個、最小1個買った…のように集計できている。(なお、集計関数はnullを対象としない。例えばユーザ2のavgは4.0となっているが、これはqtyがnullのレコードは平均の母数にも含んでいないから)
- このようにユーザごと集計値を取得することで色々な分析が可能となる。例えば「平均が最も高いのはユーザ2さんだな。今まで最も購入してくれたのはユーザ1さんだな」のように。
- なお、グループ化せずに全体の集計値を取得することで全体の平均や最大・最小が把握でき、データのアタリをつける役に立つ。
グループ化・集計関数と他の句の組み合わせ
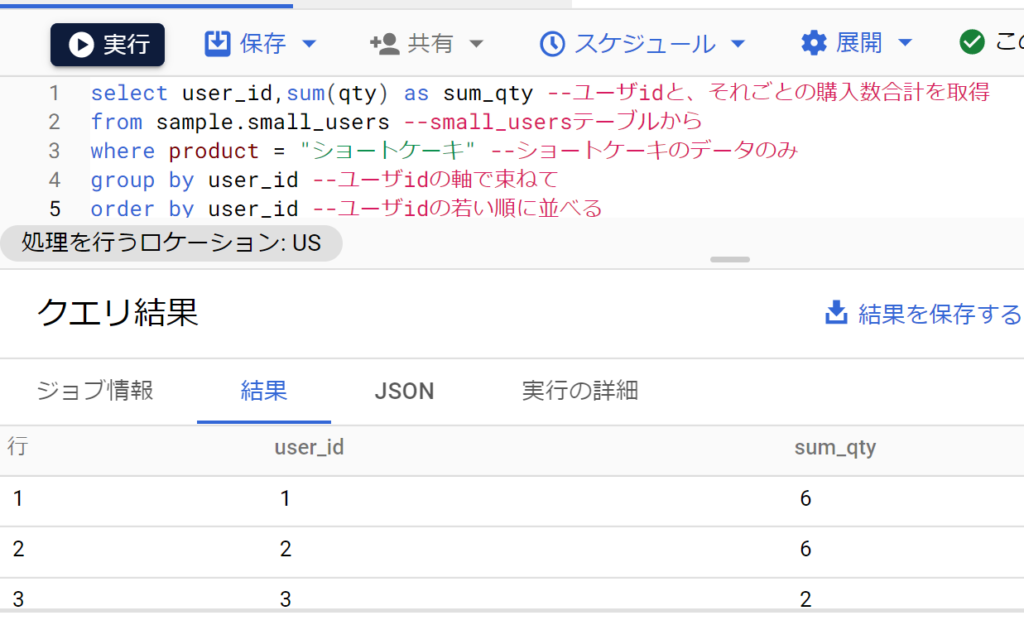
- もちろん今までのフィールド・レコードの操作と組み合わせることも可能。
- たとえばproductがショートケーキのレコードのみで、qtyの合計を求めるなど。
高度な集計関数
- さらに高度な集計関数もある。たとえば「統計集計関数」に分類される標準偏差を求める関数「データの全数である母集団から標準偏差を求めるstddev_pop(フィールド名)」や「母集団から一部を取得したサンプルから標準偏差を求めるstddev_samp(フィールド名)」など。
- これとgroup byを組み合わせることで「珍しいケース」を抽出できる。「平均±(2×標準偏差)」に約95%のデータが含まれるため、たとえば平均1.5、標準偏差が0.5の場合は1.5-2×0.5=0.5、1.5+2×0.5=2.5となり、データの95%が0.5から2.5に分布する。すると、データが3の場合きわめて珍しいケースだとわかる。
考察(一部再掲)
- SQLについて、今まではフィールド(列)やレコード(行)の操作など「データを扱う基礎」を学んできた。今回から「分析の基本」を順に学ぶ。分析とは「分類し比較する」ことで、SQLではグループ化と集計関数を用いる。
- 自分や世の中の問題を解決するには、筋の良い論点(解決策)を見つける必要がある。筋の良い論点を見つけるには、「疑問・仮説・検証」のサイクルを回すことが不可欠。サイクルを回すにはデータ分析で「検証」する必要がある(疑問・仮説までだと、個人の思い込みに留まる)。
- ただ、仮説と検証は何度も回す必要があるので、つど他者に依頼すると時間がかかる。だから、データ分析のやり方を個人で学び、自分でやれるようにして、経験を蓄積して考えを広げていくことが重要だ。
参考書籍
- 集中演習 SQL入門/木田和廣/株式会社インプレス
- データベーススペシャリスト2022年版/三好康之/翔泳社
- おうちで学べるデータベースのきほん/ミック,木村明治/翔泳社
- 論点思考/内田和成/東洋経済新報社
- 野口悠紀雄の経済データ分析講座/野口悠紀雄/ダイヤモンド社

コメント