
この記事は「データベーススペシャリスト資格に興味はあるが、どのようなものか?どう学ぶのか?」という方向けに、具体的な内容と私自身の挑戦ログをお伝えする。学び中の方や、これから学ぼうとされる方の参考になれば幸いだ。今回はSQLの利用開始について書く。
データセットとテーブルの作成
前回のおさらい
- 前回はBig Queryサンドボックスを起動し、アカウントを作成した。
- そして、そのアカウントの中にプロジェクトを作成した。
- イメージとして「アカウント」フォルダの中に「プロジェクト」フォルダを作ったイメージ。
データセットの作成
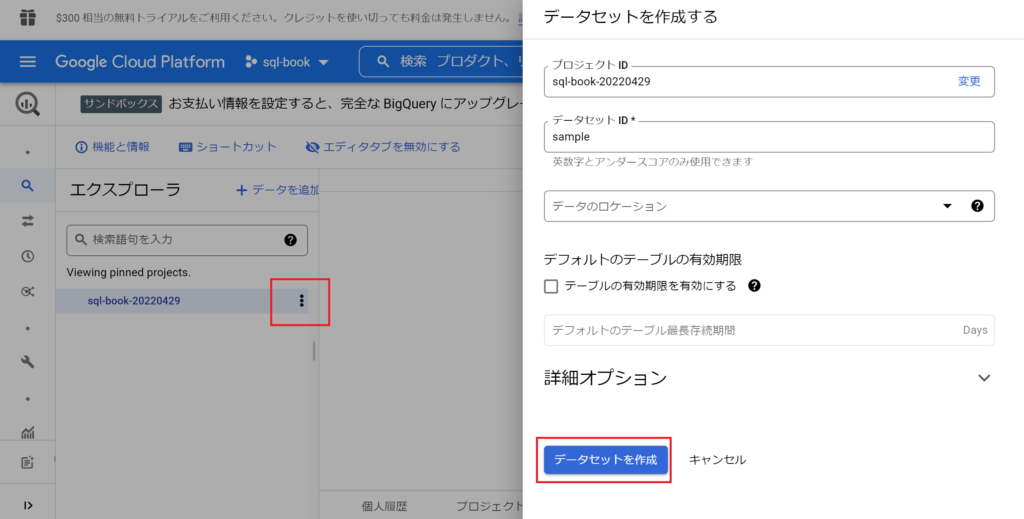
- 次にデータセットを作成する。
- イメージとして「プロジェクト」フォルダの中に「データセット」フォルダを作るイメージ。
- プロジェクト名の右側(以下図の赤枠)をクリックし、「データセットを作成」をクリック。
- データセット名は任意。今回は「sample」とした。
テーブルの作成①
- 次に、データセットの中にテーブルを作っていく。
- 言葉の復習。「すべてのデータは表形式にまとめたテーブルで管理する」「テーブルは集合(意味のあるまとまり)であり関数(入力に対し一意の出力が決まる)」
- 実際の手順。エクスプローラ(上図参照)から進める。(パソコンでもフォルダの構造とファイルをグラフィカルに見せるツールとして利用しているので、直感的にイメージしやすい)
- 先ほど作成した「sample」データセットの右側をクリックし、「テーブルを作成」をクリック。
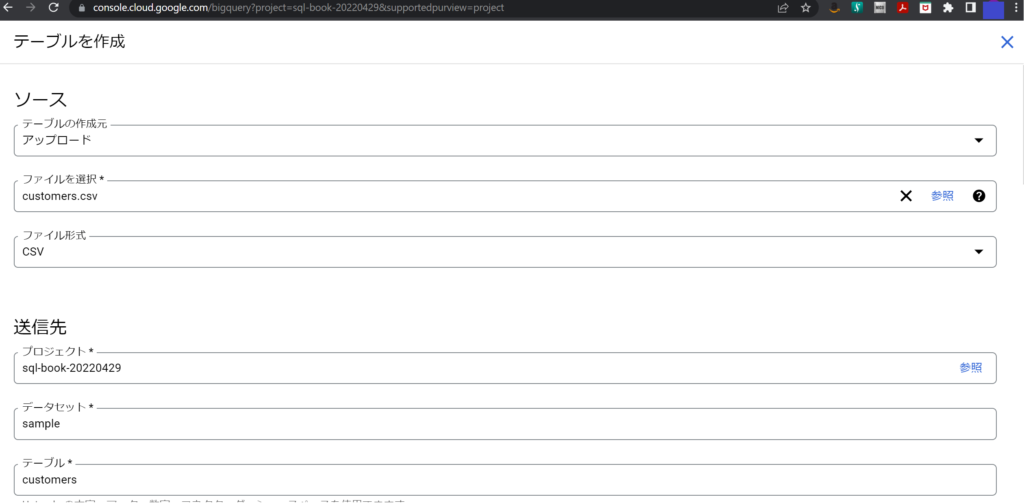
テーブルの作成ウィンドウが展開する。以下手順のとおり行う。
- 「テーブルの作成元」は「アップロード」を選択
- 「ファイルを選択」は取り込みたいcsvファイルを選択
- 「テーブル」は作成したいテーブル名を選択。この例は「customers」
- ※なお、この記事では参考書籍の特典csvを利用した。自分でcsvを用意する場合「UTF-8でエンコードされていること」「ファイルサイズが10MB未満、レコード数16,000未満」の制約あり。それ以上のデータ量の場合、Google Cloud Storageを経由する必要がある。
- ※たとえば自分でテスト用の表をエクセルで作成し、csvにして取り込みたい場合。エクセル2016であれば保存形式にUTF-8が選択できる。エクセル2013の場合は一度csv保存したあと、それをメモ帳で開き、文字コードをUTF-8にして保存するとよい。
テーブルの作成②
- 言葉の確認。「表の”列”は属性(Big Queryではカラムまたはフィールドと呼ぶ)、”行”はタプル(Big Queryではレコードと呼ぶ)」。また、Big Queryではテーブルを作成するときの列の組み合わせをスキーマと呼ぶ。
- スキーマ欄に読み込むcsvの列名(フィールド名)、タイプ、モード、説明を追加していく(列を追加したい時は+ボタンを押す)
- なお、これらの自動検出機能はあるが、今回は勉強も兼ねて手入力していく。フィールド名の打ち間違いに注意。
- 言葉の確認。タイプは「INTEGERは数字、STRINGは文字列、DATAは日付、BOOLEANは真偽値」。このあたりが良く使う。タイプを間違えるとエラーになるので注意。
- また、モードは一律「NULLABLE」(空白を許可する)にしておく。(そうでないと値nullのデータを取り込もうとするとエラーになってしまう)

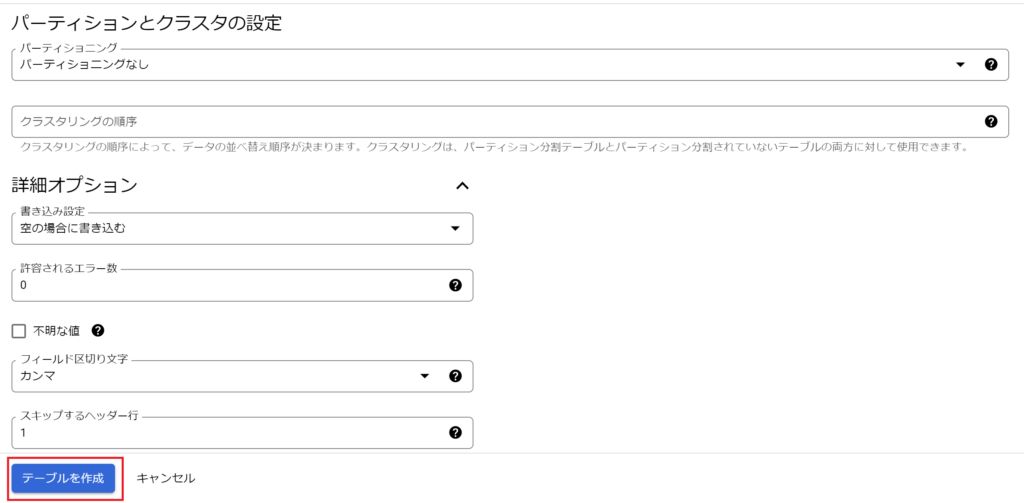
テーブルの作成③
- 詳細オプションを開く
- 「スキップするヘッダー行」に1を入力。最初のヘッダー行をスキップしてもらう。(そうでないと、ヘッダー行のタイトルがstringなのでintegerの列でエラーになる)
- 「テーブルを作成」をクリック(以下赤枠)
- 以降、おなじ手順で3つのテーブルを作成する。(「products」「sales」「web_log」)
クエリの実行・情報確認・保存
クエリの実行
- 言葉の確認。クエリとは「SQLを用いて、テーブルから必要な情報を取り出してもらうための要求」。
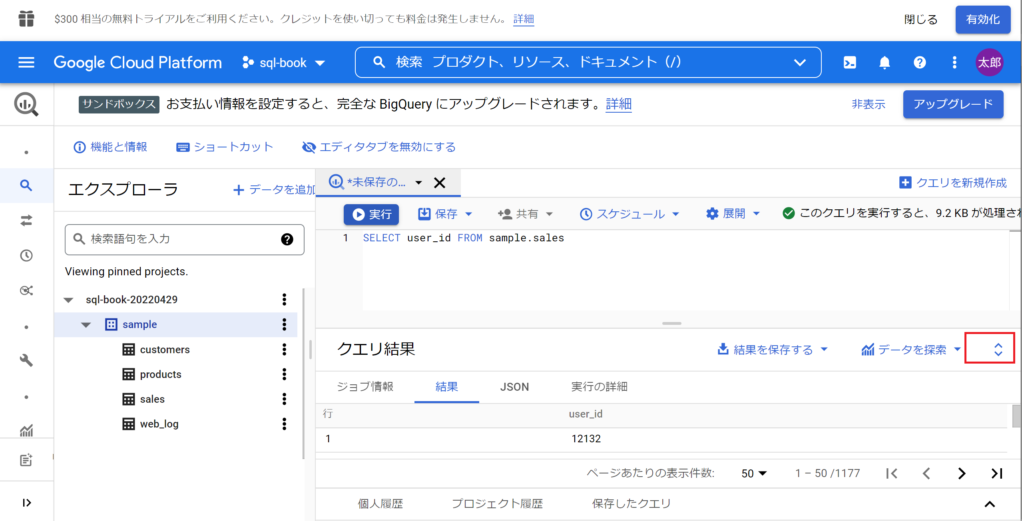
- コンソールから「クエリを新規作成」を押す。クエリエディタが新しいタブで表示される。(タブを切り替えながらクエリを作成できるようになっている。)
- はじめてのクエリとして「SELECT user_id FROM sample.sales」と入力。(なお、クエリの一部を実行したいときは、一部を選択したうえで「実行」を押す。)
- sampleデータセット内のsalesテーブルからuser_idが抽出される。
- クエリの結果は下段の「クエリ結果」欄に出力される。この表形式の実行結果を「結果テーブル」と呼ぶ。
- 「クエリ結果」右側の矢印(以下赤枠)を押すと最大化される。
ジョブ情報の確認
- クエリ結果には「結果テーブル」が表示される「結果」タブ以外にもいくつかタブがある。
- そのうち「ジョブ情報」タブをクリックし、「Temporary_table」を押すと結果テーブルに関する情報を表示できる。
- 新しいカラムを作成するようなSQLで使う場合があるので覚えておくと良い。
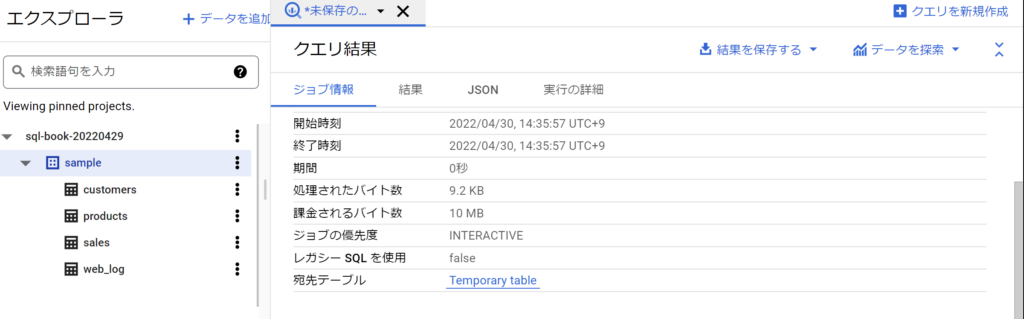
クエリを保存する
- クエリエディタ内の「保存」をクリックし、「クエリを保存」を選択。
- わかりやすいクエリ名を入力し実行する。
- あとからクエリを再利用したり、結果の正当性を他人に見てもらうなどのため。
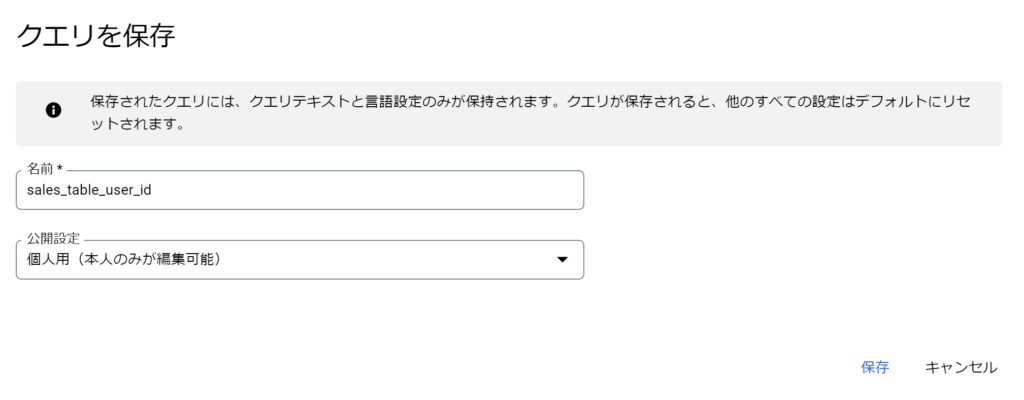
その他の基本操作
ビューの保存
- 言葉の確認。ビューとは「クエリの結果を仮想テーブルとして保存したもの」
- クエリエディタ内の「保存」をクリックし、「ビューを保存」を選択。
- プロジェクト、データセットIDは保存先のものを選択。
- 「テーブル名」にわかりやすいビュー名を入力し実行する。
- 別のクエリから参照したり、使いまわしたりするため。
- 保存したクエリやビューは、エクスプローラから選択できる。
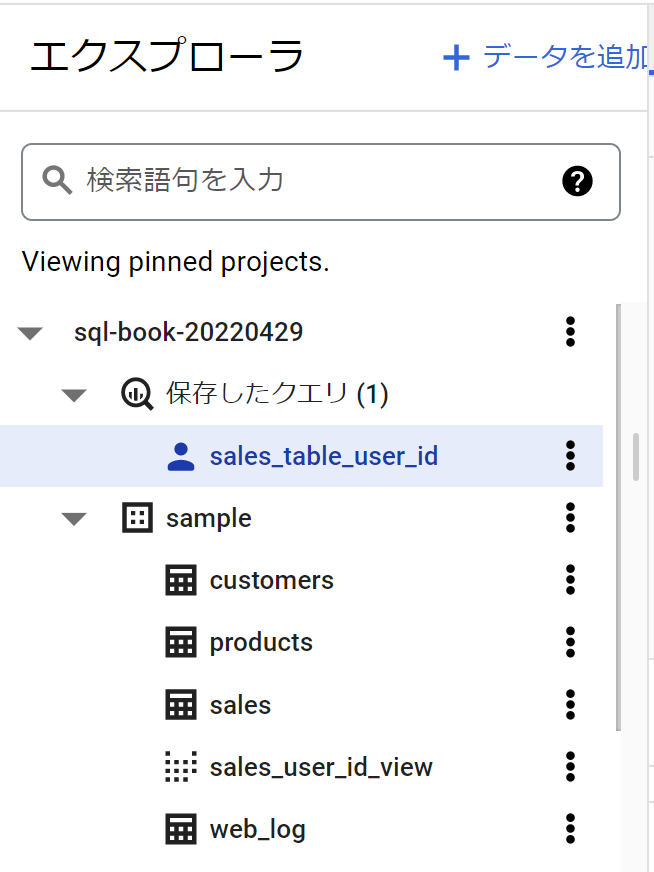
クエリの結果をテーブルとして保存
- クエリエディタ内の「結果を保存」をクリック。
- 保存先を選択。
- 目的に特化したテーブルを作成するため。
結果テーブルのデータを可視化
- クエリエディタ内の「データを検索」→「データポータルで調べる」の順にクリック。
- 結果テーブルがGoogleデータポータルで表示される。
- グラフの種類を選択するとデータを可視化できる。
クエリやジョブの履歴を表示
- クエリエディタ下段の「履歴」をクリック。
- クエリやジョブの履歴が表示される。
- エラーになったときの途中再開の手間を省くなどの用途。
簡単に復習
プロジェクト・データセット・テーブルの作成
- 復習のため、もう一つ別にプロジェクト・データセット・テーブルを作成。
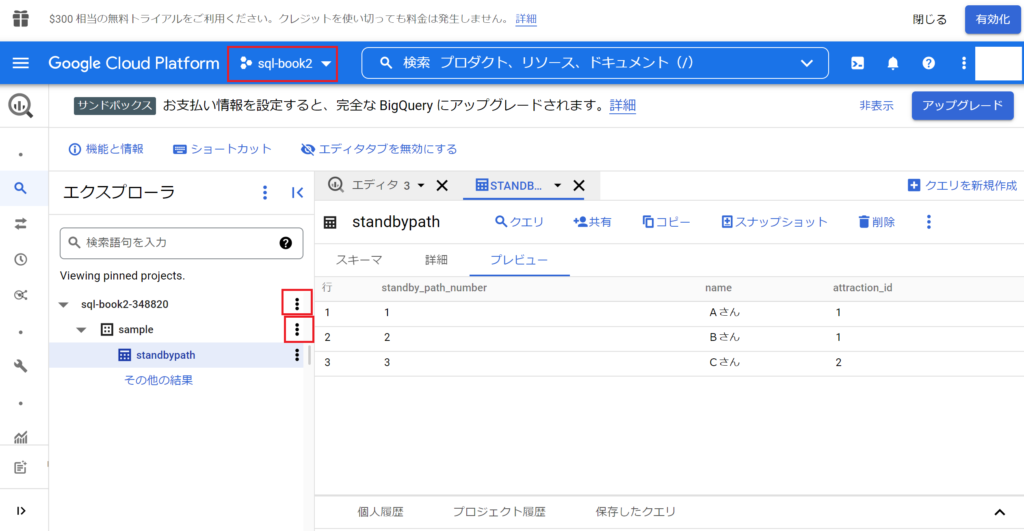
- 画面上部の「Google Cloud Platform」の右側(以下画像の一番上の赤枠)からプロジェクトを選択し「新しいプロジェクト」を選択。
- 新しいプロジェクトを作成したら、プロジェクトの右側(以下画像の赤枠)から「データセットを作成」を選択。
- データセットの右側(以下画像の赤枠)から「テーブルを作成」を選択。自分で作ったcsvを読み込み、列ごと設定は自動検出、最初の1行は飛ばす設定で実行。以下のとおりテーブルが作成できた。
簡単なクエリの実行
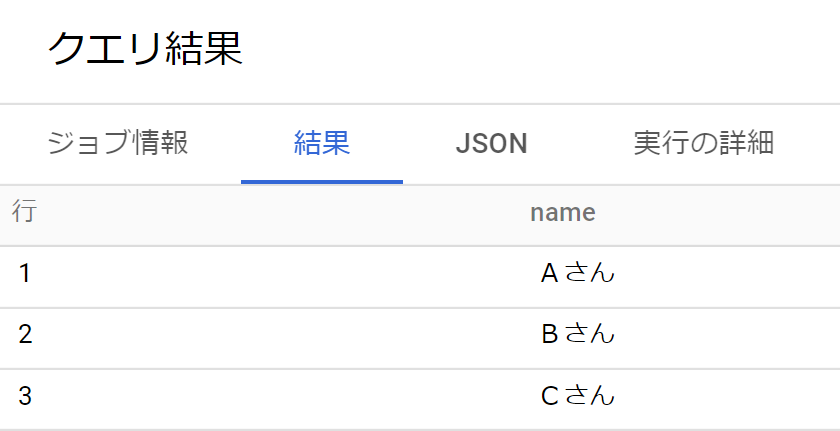
- 最も基本の「select from」を試す。name列の情報を取り出すシンプルなクエリを実行。
- 「select name from sample.standbypath」と入力。
- 以下のとおり、name列の情報のみ取り出せた。
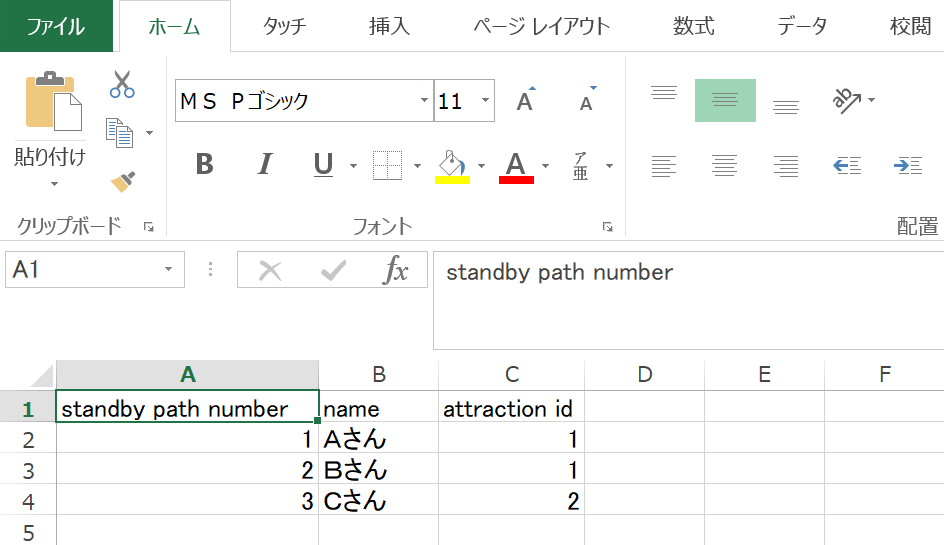
参考 自分でcsvを作る手順(エクセル2013の場合)
(手順1)エクセルを開き、表形式になるようセルに値を入力。
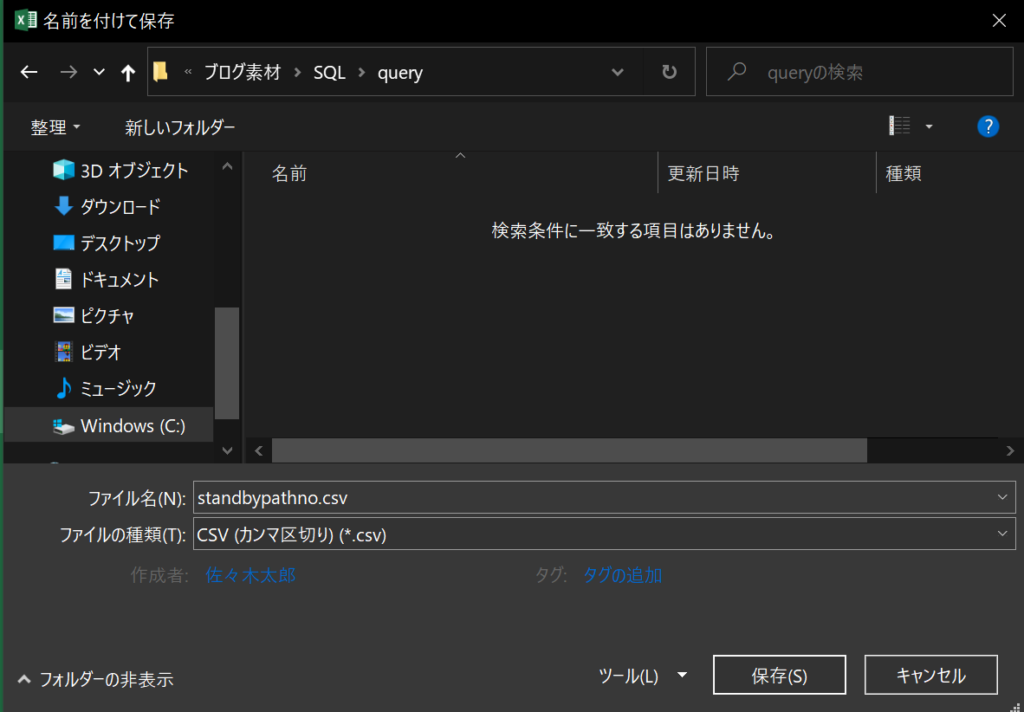
(手順2)csvで保存
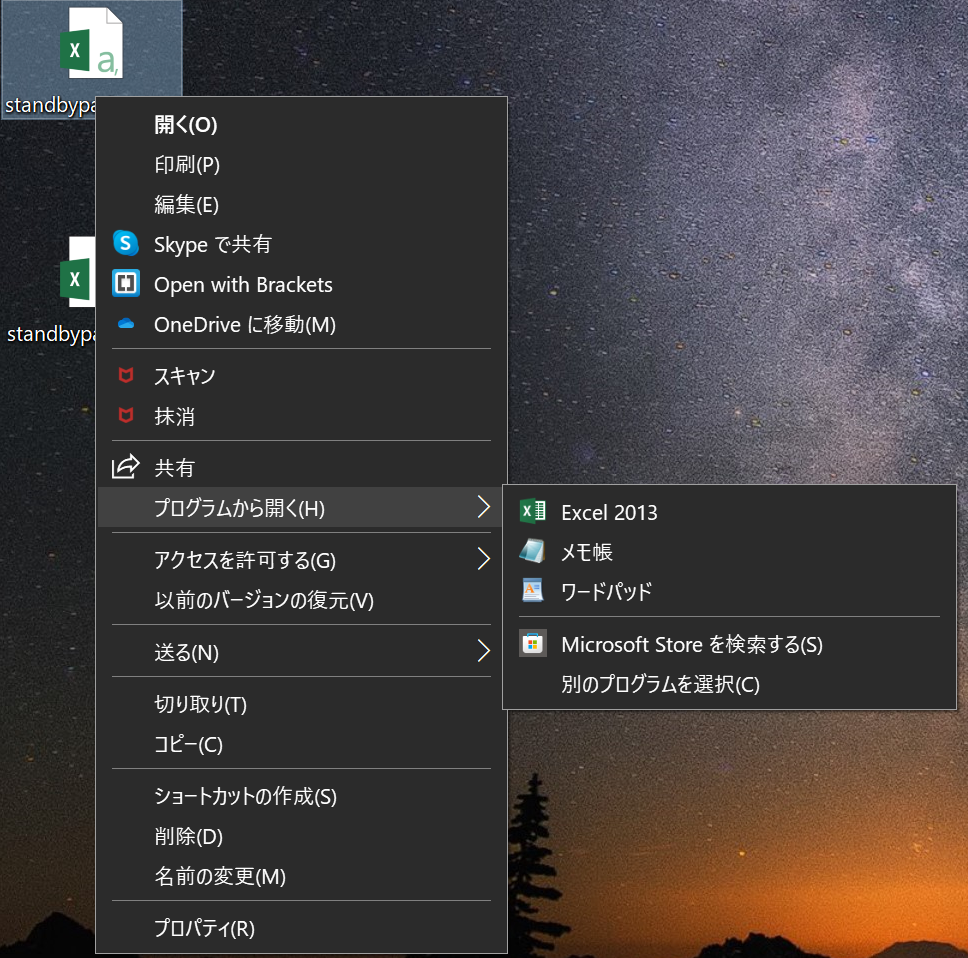
(手順3)保存したcsvを右クリック⇒プログラムから開く⇒メモ帳
(手順4)文字コードにUTF-8を選んで保存
考察
- SQLを学ぶ代表ツールとしてMY SQLがある。しかしこちらはコマンドプロンプト(文字を打ち込み、文字で結果が表示されるもの)。SQLを「試しに触ってみる」であれば良いかもしれない。ただ、「分析したいデータを用いて簡単にテーブルを作る」「大量のデータを参照・合計したり、複数のテーブルを結合・相互参照したりする」「その結果を色々な切り口から分析し、グラフィカルに表示する」などふまえればGoogle Big Queryが現状最適解。
- やはり実際に触って比較してみないとその良さは分からない。
- 「大量の生データを持ってきて、様々な切り口から抜き取る」ことはファクトフルネスな分析に極めて大事。そもそもデータが少ないと視野が狭くなるし見落としもおきる。切り口が少ないと偏ったものの見方になる。そして「グラフィカルに表示する」のも大事で、難しい相関などを用いなくてもシンプルに傾向がわかる。つまり、広く、多角的な視野で、直感的に傾向を掴める。
- まとめ。Google Big Queryは「データをまとめたテーブル」「テーブルから情報を取る命令(クエリ)」「結果の保存(ビュー)」をWindowsのエクスプローラのように作成・管理できるツール。ビューのグラフ表示なども充実し基本無料。
- このツールで「大量の生データを持ってきて、様々な切り口から抜き取り、グラフィカルに表示する」ことを実践で試してみたい。世界の事象に能動的に係り、自分だけの考察を深めるうえでの大事な武器になるだろう。(今まではエクセルだったが、扱えるデータ量と拡張性に限りがあった)
参考書籍
- 集中演習 SQL入門/木田和廣/株式会社インプレス
- おうちで学べるデータベースのきほん/ミック,木村明治/翔泳社
- FACTFULNESS/ハンス・ロスリング,オーラ・ロスリング,アンナ・ロスリング・ロンランド/日経BP社

コメント