
はじめに
- この記事は、2022年10月データベーススペシャリスト試験(以下、DB試験)の学習時に書いたもの。
- 目的は、学びを整理・体系化してすぐ引き出せるようにすること。
- そうすれば、試験でもより短時間で正確に回答できるようになり、合格率が高まる。
- なお、記事の太字は試験直前にざっと見返すことを想定した部分。
学びの戦略・計画
試験の構成と戦略
- DB試験は午前1、午前2、午後1、午後2の4部構成。私は午前1免除のため、それ以外について概要と戦略を記載。
- ①まず、午前2。25問のうち約半分は過去問の再掲または改変なので、過去問中心に学んでおき、確実に回答できれば50%は取れる。残りの新規問題も、ちゃんと読んで考えれば4択を2~3択には絞れる。これで合格ラインの60%以上を狙うのが基本戦略。
- ②次に、午後2。2問中1問の選択式で、うち1問は「8~9割が、ER図とスキーマの完成(論理設計)で構成される問題」となる。よって論理設計について解き方のプロセスと知識を学び、トレーニングを続けて得点できるようにする。さらに、問題構成の残り1~2割の部分(業務改善にともなう設計などで、全体の読解力が試される)で半分くらいは取り、総計で合格ラインの60%以上を狙うのが基本戦略。
- ③最後に、午後1。3問中2問の選択式で、うち1問は上記②の論理設計がコンパクトになったもの、のこり2問は物理+SQLとなる。1問は論理設計、残り1問はSQLが多めの問題を選び、確実に得点できる部分を取っていき、総計で合格ラインの60%以上を狙うのが基本戦略。
学びの計画(全般)
- まず、「そもそもデータベースとは?」「ER図やスキーマとは?」「SQLとはどんなもの?」などベースとなる知識の大まかな理解が必要。
- おすすめは「おうちで学べるデータベースのきほん/ミック、木村 明治/翔泳社」。初学者が持つ「DBへの取っつきにくさ」の緩和に重点が置かれつつ、勘所が詰まっている。
- ここから学習を始めつつ、本試験1週間前に軽く見返すと最も上位の知識がおさらいできる。
- また、前述した「DB試験の構成」「過去数年の出題傾向」「効率的な学習戦略」など試験そのものへの理解が必要。
- おすすめは「データベーススペシャリスト2022年版/ITのプロ46 三好康之/翔泳社」。過去10年以上の設問一つ一つに、十分な時間をかけて分析された三好先生みずから戦略のエッセンスを執筆されている。
- ここで自分の学習戦略を計画しつつ、本試験1週間前に軽く見返すと学習戦略のおさらいができる。
学びの計画(午前2)
- 戦略に記載のとおり、過去問の学習がメイン。
- 学習範囲として、最低限過去5年分は抑えたい(2年くらい前からの再掲が多いため)。そのうえで、重複問題をのぞき、データベース分野を中心に、出来るだけ幅広い問題に対応できるようにする。
- 学習方法として、「設問と回答の組み合わせの暗記」はNG。少しひねられると間違えてしまうし、新規問題も対応できなくなるため。
- すなわち、重複を排除したできるだけ広い範囲の過去問を、回答プロセスも含め学ぶ必要がある。
- おすすめは「2022年度版 ALL IN ONE パーフェクトマスター データベーススペシャリスト/TAC」。重複をのぞいた約100問を厳選し、回答プロセスまで含め解説されている。
- TACのDB対策講座(本科生)は、本テキストにくわえ知識の解説動画と、回数性のオンライン質問がついてくる。「講義形式の方が頭に入るし、続く」という方にはこちらもおすすめだ。
- 本試験1週間前には、ALL IN ONEを軽く見返す(必ず、1問ごと回答プロセスと必要知識を頭に浮かべながら)のが効果的。
- なお、本試験に慣れる意味で、過去問5年分を時間を測りながら解く練習も必要となる。これはIPAの過去問から印刷すればOK。本試験1週間前には、過去問5年分の形でも軽く見返す(主に時間戦略を振り返りながら)。さらに、アウトプット練習ができればベスト(私はR3 AM2で実施)
- さらに念押しとして、最も出題が多いデータベース分野の学習範囲を更に広げる。おすすめは前述の三好先生の付録についてくる「午前問題218問完全版」。TACのテキストや過去問5年分と被らない問題について、ざっと回答プロセスを読んでおくと、さらに対応力が高まる。本試験1週間前に、軽く復習しておくとベター。
学びの計画(午後2)
- 戦略に記載のとおり、「ER図とスキーマの完成」の学習がメイン。
- 過去問を実際に解きながら、午後2向けとしての知識(多重度、スーパータイプ、連関エンティティ等)および回答プロセス(時間内に回答を全て埋める方法)を学んでいく。
- おすすめはTACのDB対策講座(本科生)についてくる、過去問演習の解説動画。先生が臨場感と熱意たっぷりに、知識とプロセスの勘所をレクチャーしてくれる。ここで学んだ知識と回答プロセスを自分なりに整理し、過去問を2~3問解きブラッシュアップすると効果的。
- なお、前述の三好先生の本には「午後2重要過去問」が掲載されているので、どの過去問を解くか悩む場合は参考にするとよい。
- また、午後2は実技試験なので慣れが必要。IPAの講評にも「習慣を身に着けてほしい」とある。よって試験1カ月前くらいから、毎日少しづつでも、実技をしておくと効果的。(私は午後1問題4問、午後2問題2問を4回ほど繰り返した。これは、コアとなる実技力を中心に鍛えたかったから)
- ある程度慣れてきたら、時間を測って解き自分の実力を試す。改善点を見つけ対策する。TAC本科生であれば公開模試を活用するのも良い。(私はくわえて、試験1カ月前に令和3年PM2で実施)
- 本試験1週間前には、知識と回答プロセスの総復習が必要。私は、知識は三好先生のテキストに書き込み、回答プロセスは記事にまとめている。よって「今まで解いてきた過去問の設問を見返し、知識とプロセス思い返し、答え考え、答え合わせ」を繰り返し、テキストに書き込み、記事は再編する。
- なお、この振り返り範囲にはTAC公開模試(動画解説)および直前まで行う実技トレーニング問題を含む。
学びの計画(午後1)
- 戦略に記載のとおり、「論理設計」および「物理+SQL」の学習がメイン。
- 午後2と大きく異なるのは、「論理設計」のうち「ER図とスキーマの完成」が完璧なだけでは合格ラインに達せないこと。(ここ数年の傾向では、全3問中で論理設計は1問で、そのうちER図とスキーマの完成は約3~8割くらいの配分だから。つまり100点中15~40点くらいの配点)
- そうなると、それ以外の確実に得点できる部分で、出題頻度が高い傾向にあるものを中心に学ぶことになる。おおむね以下3つ。
- ①まず、基礎理論。これは候補キーの洗い出しや正規化を行うもの。もちろん必出ではないが、やり方を知っていれば得点しやすく、基礎知識なので抑えておいて損はない。
- ②次に、SQL。ここ数年で出題頻度が高まっており、おそらく社会ニーズに基づくものと思われる(業務の見える化だけでなく、データの蓄積と分析が必要)。
- ここ数年は「論理設計1問、物理+SQL2問」や「論理設計1問、物理1問、SQL1問」などの構成であり、ほぼ避けて通れない。
- ただ、SQLは実際に手を動かさないと身につかない。もし実務経験が無い場合、「集中演習 SQL入門/木田和廣/株式会社インプレス」はおすすめ。初学者でもデータ分析実務でSQLを扱えるように、本質的かつわかりやすい解説と、大量の練習ドリルがついている。
- もしSQLの基礎が体得できている場合、過去問ベースで試験向けの知識と回答プロセスを学んでおく必要がある。
- ③最後に、物理設計の再掲・改変問題。上述の「ER図とスキーマの完成」「基礎理論」「SQL問題」だけでは合格ラインに届かない可能性があるため。(そこそこ難しいので、満点は難しい。さらに、配分が不明瞭。頑張って8割取れたとしても点数は30~50点くらいか?)
- となると、のこる「物理設計」でも半分は回答できないと厳しくなる。
- ここでのおすすめは前述の三好先生の本。「SQLや物理は避けて通れないが、出題範囲が広すぎる」ことをふまえ「物理+SQLの最重要過去問」および「午後1の物理向けとしての、午後2重要問題」が掲載されている。少なくともこのあたりは一読し、知識やプロセスは抑えておきたいところ。
- 試験1週間前には、基礎理論・SQL・物理最重要について、解いてきた過去問を見返し、知識とプロセスを再編・おさらいすると良い。
本試験の注意点
事前準備
- 受験票。情報確認、写真貼り付け
- 交通手段。事前に確認、余裕をもって到着
- 机の上に置くもの。シャーペン、消しゴム、時計、ハンカチ、目薬等
- 防寒対策。ベスト、カーディガン等
当日の注意点(私の場合)
- 前日は早めに寝る。コーヒー少なめ、寝る2時間前スマホ厳禁
- 心身ともに良い状態に。「ここまでやったのだから落ち着けば6割取れる」が理想
- トイレ対策。コーヒーは飲まない。試験開始直前にトイレ
- 切り替え。午前2が終わったら、午後1に集中
- 昼食。しっかり取る。具沢山おにぎり、卵、バナナ、甘いナッツバーなど糖分を補給
- 気分転換。小休憩のあいだ、外に出て軽く体を動かし深呼吸
- 昼寝。15分ほどが効果的
午前2
- 氏名・受験番号などの確実な記載。記入し忘れで落ちるのは本当にもったいない。(問題と答案が配られた時点で、必須記入項目は確認できるので、抑えておくこと)
- 約5割の過去問の再掲は確実におさえること
- しかし、再掲でも選択肢の順が入れ替わったり、内容が少し変わる場合がある
- よって過去問の再掲こそ焦らず、じっくり設問を読み、知識もふまえしっかり考えて回答。
- 残り5割の新規問題も、少し考えれば選択肢を絞れるのであきらめないこと
午後1ー①(問題の選択まで)
- 氏名や受験番号、とくに「選択した問い」のチェック。
- クリアな頭で。とにかく頭をよい状態にもってくること。
- 午後1の選択問題について。慎重・迅速に得意問題を。
- 問の表題に「○○に関する」とあるので、まずそれで絞る。
- 上記戦略に基づき、まず1問は「データベース設計」。(仮に2問あれば大いにありがたい)
- もう1問は「SQL設計」があれば優先選択。(データウェアハウス、○○およびSQLの設計なども含む)
- もし残り2問とも「データベース実装」系だった場合。少しでもSQLの配分が多く、過去問に近しいものを選択(完全に物理のみの問題、バックアップ・復旧・データ所要量計算などは排除)
- 以降は選択の具体例。
- R3(令和3年)は問1論理設計(データベース設計)、問2性能(データベースの実装)、問3SQL(テーブルの移行およびSQLの設計)。よって問1は確定で、もう1問は問3を選択しておく形(SQLが多いぶん、物理寄りの知識があまり求められない)
- R2(令和2年)は問1論理設計(データベース設計)、問2レプリケーション(データベースの実装)、問3DWH(データウェアハウス)。よって問1は確定で、もう1問は問3となる(問2は物理なので除外)
- H31(平成31年)は問1論理設計(データベース設計)、問2トリガとデッドロック+SQL(データベースでのトリガ実装)、問3索引とテーブル構造+SQL(部品表の設計および処理)。問1は確定で、トリガについて過去問知識で答えられそうなら問2、そうでないなら問3となる。
- H30は問1論理設計(データベース設計)、問2参照制約+SQL(データベースでの制約)、問3所要量計算(物理データベースの設計と実装)。よって問1,問2となる。
- H29は問1論理設計(データベース設計)、問2排他制御(トランザクションの排他制御)、問3SQL(テーブルおよびSQLの設計)。よって問1,問3となる。
午後1ー②(問題の選択以降)
- 上述の学習を進めてきて、戦略的に問題を選択したならば、「時間配分の計画を立て、とにかく全部の答えを埋める」(まずはざっと)がきわめて大事。
- なぜなら、午後1は「短い時間のなか、確実に取れるものを取って、6割以上を目指す」戦いなので。
- たとえば、ER図とスキーマの配分が少ないうえ、かなり難しい、ということも当然想定し得る。(当然、そのような時は、それ以外の部分が以外と簡単な可能性が高い)
- 繰り返しだが、上述のとおり準備を進め、一定以上の読解力があれば6割以上は取れるように問題は設計されているはず。取れるものを取るため、難しいところは深入りしすぎないことも大事。
- 共通の解き方は以下。ER図とスキーマ・基礎理論・SQLなどのコツは別途整理。
- ①タイトル・見出し・小見出しに線を引き、その下1~2行に目を通し、「構造」把握
- ②大きな構造ごとに長く横線で区切りブロック化する。これで長文がぐっと読みやすくなる。
- ③設問に丁寧に線を引き、システム表現に焦らず、ユーザーニーズ(何がしたいか)に着目し、表や図も注意し、本文と設問の紐づけを行う。
- ④本文、設問、(あればRDBMS仕様)、パズル要素の4つをベースに、順に回答していく。
- この流れを体感で掴み、慣れる。直感でアテがつかないものは深追いしない。全体で6割取れればよいし、後から見えることもある。
- ただし何らか答えは書く。部分点がもらえるかもしれないため
- 繰り返しだが設問に注意。絞り込みのヒントであり、聞かれたことに答えるため
午後2
- 氏名や受験番号、とくに「選択した問い」のチェック。
- クリアな頭で。とにかく頭をよい状態にもってくること。
- 午後2の選択問題は、論理設計で確定。
- それ以外の注意事項は、午後1ー②で記載と同じ。午後2でもまずはざっとが大事。
論理設計のコツまとめ
- 午後試験のうち、論理設計(ER図とスキーマの完成)のコツを、現時点で以下のとおり整理。
- これは、理論(TACの講義動画、TACのテキスト、三好先生のテキスト)を元に、実践(実際に自分が解いて、振り返って有効だと思ったもの)をふまえて整理したもの。
- 午後1も午後2も時間が短く、とくに午後2は疲労も溜まっているので、パターン化しておき慣れておくことが重要。
①本文、設問
- 本文と設問の読解。これは上記「共通の解き方」参照。
②回答計画
- 時間配分。ブロック紐づけと過去比較からなる。
- ブロック紐づけとは、本文の記述ブロックが、設問それぞれにどう紐づくかアテをつけること。
- 過去比較とは、過去問ベースの練習における「本文ページ数と所要時間」を記録しておき、本試験の際にこれと比較して時間配分を考えること。
- 私の場合、午後2配分は「計画10分、現行(マスタ・トランザクション)は6ページに対し75分、新規は3ページに対し25分、見直し10分」だ。
- また、午後1配分は「計画5分、現行は2~3ページに対し20分、新規は1~2ページに対し15分」だ。
- 注記確認。設問前と設問内からなる。
- これは見逃すと、せっかく理解できていても全て間違いになるリスクがあるので注意したい。ゲームルールなので、さっとチェックし過去問と差異が無いか確かめること。
- 設問内とはもちろん、設問の中に記載されている制約だ。設問1はOKだが、設問2は見逃した…ということがないよう、各設問の後ろに「CHK」とだけ書いておくと忘れない。
- 設問前とは3か所。「冒頭の”問題文中で共通に使用される表記ルール”」「ER図やスキーマの前にある”概念データモデル及び関係スキーマの設計”などの注記(午後1は簡素)」「設問直前にある太字部分」のこと。
- たとえば「マスタとトランザクション間のリレーションは必要か」「0を含むかの記載ルール」「エンティティタイプの追記も必要か」などだ。
- また、この時点でパターン把握する。(今回は、過去問のどのパターンに該当するか?それに合った回答プロセスをすぐ適用することで大幅に時間短縮できる)
②(補足)パターンごと対処方針(午後2)
- 直近3年(R3,R2,H31)ではER図とスキーマ本体は「マスタとトランザクションを別々に記入」「0を含むかの記述は不要」「エンティティタイプは穴埋め形式で1~2個程度」とかなりやりやすい問題。
- かわりに、業務改善後について”ミニER図やスキーマ補記”、”SQL穴埋め”、”本文ヒントを元にした数十字の回答”などが出題された。
- なお、令和4年のTAC公開模試もこの形式。
- この出題傾向は、おそらく社会的背景(現行分析だけでなく、ユーザニーズのくみ取りと改善後業務のイメージアップがより大事に)と、採点者側の事情(回答欄がとてもスッキリする)によるものと推測。
- この直近3年パターンは、自信を持って落ち着いて取り組む。回答プロセスと知識に基づき、忠実に積み上げ回答が可能なため。業務改善後も積み上げ回答と読解力の複合。
- 出題の可能性はやや低いが、それ以外のパターンは回答プロセスを過去問中心にざっと抑えておく必要がある。
- まずH29は「マスタとトランザクション間の関係も書く」「0を含むかの記述は不要」「エンティティタイプの追記はなし」と、直近3年パターンにきわめて近い。ただ、設問2,3でのアウトプット表現が少し特殊なので、慣れておくと良い。
- 次にH24は「マスタとトランザクション間の関係も書く」「0を含むかの記述は不要」「エンティティタイプは穴埋めで4個ほど(簡単)」と、直近3年パターンにかなり近い。設問2で改善後業務のER図はエンティティの追記もあり(ただし2~3個)。自信を持って取り組めるが、念のためざっと見返すと良い。
- 最後にH25は「マスタとトランザクション間の関係も書く」「0を含むかの記述は必要」「エンティティタイプは大量に空白に追記。さらにスキーマも空白を埋める」とてんこ盛り。回答プロセスで求められるものは基本的な知識と読解力のみであるが、空白が多いので大量かつ丁寧な試行錯誤が必要となる。出題の可能性は低いので、念のため目を通しておくくらいにとどめる。
②(補足)パターンごと対処方針(午後1)
- 直近3年(R3,R2,H31)では設問1でER図とスキーマが問われている。「マスタとトランザクション間の関係も書く(ミニサイズなので)」「0を含むかの記述は不要」「エンティティタイプは穴埋め形式で1~2個程度」と確実に得点しやすい部分。
- 設問2以降はいくつかパターン分岐する。R3は基礎理論と論述問題、R2は改善後業務(全体)のER図とスキーマ、H31は決定表と改善後業務(一部)のER図とスキーマ。
- なお、この傾向は過去数年でも同じものが多い。設問1は同上で、設問2以降が分岐。H30はサブタイプ分割と改善後業務(一部)のスキーマ、H27はSQLの穴埋め。
- 少し特殊なパターンとして、H29は設問1が基礎理論、設問2がER図とスキーマ(0を含むかの記述が必要)、設問3が改善後業務(一部)のスキーマ。とはいえ「0を含むかの記述」は殆どが基本パターン(多側のA●→○1側のB)だったので、このパターンが出ても焦らず対処できるようにしたい。
- 午後1,午後2に共通するのは「いま(現行モデル化)とねがい(改善要望)でみらい(新モデル)をつくる」力が求められていること。よって、優先度が高い振り返りは“過去3年分中心に”、”現行モデル化と新モデルについて「なぜその答えか」と「どうしたら早く答えられるか」を考え”、”実際に手を動かして作った自分なりのアウトプットを再確認“することと認識。
③突き合わせ
- 直前記載、外部キー、リレーション、サブタイプ、連関エンティティ、本文紐づけ、列名下線転記チェックとなる。
- これらはすべて、ER図やスキーマを見て行う作業。よってスキーマは問題冊子、ER図は回答用紙を用いると突き合わせで見れて効率が良い。
- まず直前記載とは、ER図やスキーマの直前に「~を元に図1、図2を作成した」とある部分のこと。これらは本文の区切りであると同時に、図への説明なのでヒントが埋まっていることがある。
- 次に外部キーとは、スキーマ内で既に外部キーが明示されているものについて、リレーションを確かめ、なければER図に補記する作業。(主キー兼外部キーにも注意)
- 次にリレーションとは、ER図で既に線が記載されているものについて、スキーマにキーが記載されているか確かめ、なければスキーマに補記する作業。(ただし、キー名称の確定は本文を読むとき)
- 次にサブタイプとは、ER図またはスキーマからスーパタイプ・サブタイプ関係を読み取る作業。ER図であれば丁度良い位置に配置されていることが多く、スキーマであれば1段落下げや区分・フラグの管理などヒントがあることが多い。(排他サブタイプ、共存サブタイプ、親に複数のスーパタイプを持つサブタイプなどの特徴を知っているほど、パズル的に埋まっていく)
- (なお、私はスーパタイプから継承する主キーを書き漏らすことが多かったので、先に一旦回答欄に書いてしまうようにしている)
- 次に連関エンティティとは、ER図またはスキーマから連関エンティティを読み取る作業。ER図であれば「表名+表名」のエンティティ名(例:大会運営サービス)があればいかにも怪しい。スキーマであれば「主キー・主キー」や「主キー・主キー・属性」などが怪しい。
- 次に本文紐づけとは、各スキーマと本文のどこが紐づくかざっとチェックすること。大まかには、スキーマの並び順に本文も並んでいる。かつ、本文中の小見出しや、本文内の「○○は…」がエンティティ名になっていることが多い。もし“見出し”や”○○は…”があればより早く当てつけ確定できるし、なければ一旦は並び順だと思い大まかに当てつけしておく。
- なお、午後2の場合、まずマスタ系はサービス提供元・サービス提供先・サービス(例:企業、顧客、商品)について語られる。次に、トランザクション系は「~のやり方」などで語られる。大まかにはこう分割される。(なお、マスタやトランザクションの一部記載は、それぞれのブロックに少しづつ分散配置されている)
- ここまでの作業を行うと、次ステップで本文を読むとき効率が良い。まず、ある程度の業務知識とER図とスキーマの突き合わせをすることで「おそらくこうだろう」と仮説が立てられるので、仮説検証アプローチが取れる。
- これは極めて重要で、本文をいきなり読んで時間内に完璧に回答するのは不可能に近い。「仮説検証アプローチをとり、かつ十分に練習して時間丁度に全部(考えたうえで)埋められる」くらいの、知識と経験と実技練習が試される良問だと感じる。
- さらに、本文の記載箇所をあらかじめ絞り込んでおくことで「おそらくここに記載がある」と確信をもって回答できる。
- 最後に、列名下線転記チェックとはいわゆるケアレスミスの防止。列名を間違えたり、下線(主キーや外部キー)が抜けたり、回答用紙の記入箇所を誤ったりしていないか確認する。
④本文読解
- まずはざっと、当てつけ順に、?と”コト”は分け、○○コード追記時注意、直接回答用紙、最終チェック。
- 最も大事なのは、”まずはざっと取り組む”こと。具体的には、当てつけ箇所を前から順に読んではいくのだが、「?」と思う箇所は一旦マークしておき先に進むこと。それにより問題全体を俯瞰でき、時間内にバランスよく回答できる。
- (参考:私の失敗談)R3 PM2 問2のエンティティタイプ空欄(ア)、R3 PM1 問3のSQL3の読解などでハマってしまった。
- 次に、事前に行った当てつけを元に、本文について上から順に、ER図・スキーマと三位一体で読んでいく。
- これは、原則として本文について前から1行づつ読んでいき、「反応すべき表現」が出てくる都度ER図・スキーマを確認していく、丁寧な積み上げの作業になる。
- なお、今までの過去問だと、各設問の最初のあたり(午後2のようにマスタ・トランザクションの完成が各々分かれている場合は、そのそれぞれ)は本文・ER図・スキーマが完成していることが多い。
- これは恐らく、チュートリアル的なものだと思われる。
- たとえば、R3 PM2 Q2 設問1の最初(社内組織・顧客組織)、R2 PM2 Q2 “図2業務の流れ”における”汎用品発注”、H31 PM2 Q2 P24記述”~に対して”という表現などだ。
- このとき大事なのは、過去問を解いて表現や図の読み方に慣れておきつつ、チュートリアルを丁寧かつ迅速に確認し、もし自分の知識と差があればその部分は意識したうえで、それ以降の読解に取り組むこと。
- そのうえで、冒頭に述べたとおりまずは一通り終わらせ、埋まった箇所もヒントにしつつ全体を補完すること。(例えばR3 PM1 問1の空欄d。本文に「購入数×商品単価」とあり、すでにスキーマに商品単価は書いてあるなど)
- なお、表や図は大きなヒントであり、最初と最後に見る。本文に紐づく表・図は「何がしたいか」を掴みやすいので、本文の各ブロックとあわせてまず読んでおくと良い(最初)。そのうえで、エンティティやスキーマを決めたら、表や図が作れるかの観点で見直しを行う(最後)。
- なお、スキーマには、本文の記載箇所を紐づけ(たとえば1-1など)しておくと、見直しの時便利。
- なお、このとき、反応すべき「表現」は慣れの世界である。ただし、完璧に反応できずとも、事前に仮説がある程度あれば、「どこかにあるはずだ(なければ、一旦保留)」として補完できる。
- 次に、「コト」(業務の流れや、プロセス)に関する記載はトランザクションなので、マスタに係る作業をしているときは一旦マークして後に置いておく。
- 次に、スキーマに「〇〇コード」を追記する場合は、外部キーである可能性が高いので波下線を忘れず、かつER図にリレーションも忘れず書く事。
- なお、リレーションを書くときの多重度は…基本は「多側に外部キー」である。また「主キーを共有している関係なら1:1」である。あとは(1)本文の記載・(2)他の類似する関係・(3)常識・(4)業務知識の順に照らし合わせ答えを決める形になる。
- なお、読んでるスキーマ・エンティティの近くに空欄エンティティがある時は注意。もっとも近く、分かり易い位置に配置されているので。(例:「締め契機」の真下に空欄アがあるので、「締め契機」とのリレーションまたはサブタイプか?とアテがつけられる)
- 次に、「回答は直接回答用紙へ」。とくにスキーマは列名が多いので、一度設問用紙に書いて、そのあと回答用紙に転記するという時間はないため。
- ただし、スキーマもER図も誤った場所に書いてないか、書き忘れがないかは最終チェックすること。
- その他認識しておきたいことを記述。午後2のトランザクションのスキーマを穴埋めするときは、やはりトランザクション表の列名追記が主となる。ただ、マスタ表の列名を追記する場合があり、これは本文に”これ見よがし”に書いてある。ようは「午後2のトランザクションスキーマ穴埋めで、マスタ系はこれ見よがしなヒントあり」となる。
- また、リレーションを引くとき、結果としてサブタイプからの線がすべてスーパタイプからの線に集約されることがある。
④(補足)本文表現のパターン例
- あくまで参考(必ずしもこの表現である訳ではない)だが、スピード向上のため、過去問で用いられた表現を記述。
- 主キーに関する表現。「識別し、~ごとに、付与し、~の別に」。一意性にかかわる表現が多い。
- 属性に関する表現。「~をもつ、登録し、記録し、設定し、~を用いる、保持する、管理する、決めている、指定する」。データ管理にかかわる表現が多い。また「計算式や表を実現するには、どんな属性がいるか考えるパターン」もある。
- 外部キーに関する表現。「属している、対応する、~に対して、位置づける、集約し、基づいて、関連付ける、~について~が分かるようにする、~ごとに~を決めている」。関係にかかわる表現が多い。上記の管理する属性が、他エンティティ名のパターンも勿論ある(例:PB商品は、どのチェーン法人のものかを持つ⇒チェーン法人は外部キー)
- スーパタイプに関する表現。「~には、~と~があり、~で分類している」「~と~を併せて~と呼ぶ」。分類・集約にかかわる表現が多い。なお、「該当する(属する)」「含まれる」「~は、~としても管理する」など、包含にかかわる表現もある。
- 連関エンティティに関する表現。「~と~の組み合わせ」「構成」「レシピ」など、上記属性・外部キーから多対多関係が読み取れるもの。
④(補足)スーパタイプやサブタイプの知識
- スーパタイプは、サブタイプが排他的なら区分、共存的ならフラグを持つ。
- サブタイプの主キーはスーパタイプと同じ。ただし、他から参照されるなら区別できる名前に。
- 複数スーパタイプをもつサブタイプの場合、どれか一つ(大抵、一番最後に登録されるもの)のスーパタイプ主キーを引き継ぎ、他のスーパタイプの主キーは外部キーとして持つ。
⑤-1 改善後(ER図とスキーマ)
- 現行のER図とスキーマ完成のあと、改善後業務のER図とスキーマを作成する設問。
- 基本的には、改善後業務についても現行と同様の手順でER図とスキーマを埋めていく。
- 注意点として、元の設計も場合により参考にすること。
- (例1:改善後のスキーマを検討するとき、「改善前のスキーマ+変更点反映」で答える(R3 PM2 Q2))
- (例2:改善後のリレーションを検討するとき、「改善前のリレーション+変更点反映」で答える(R2 PM2 Q2))
- (例3:多段階抽選方式と、ポイント有効期限への対応。前者は現状をふまえる。後者は業務知識で答える(H31 PM1 Q1))
⑤-2 改善後(SQL)
- 現行のER図とスキーマ完成のあと、改善後業務の一部についてSQLの穴埋めをする設問。(R2 PM2 Q2、H27 PM1 Q2)
- 基本的には、SQL問題の解き方と同様の手順。すなわち本文や表と紐づけ、設問の制約に注意し、知識を用いてパズル的に埋めていく。
- 重要なのは、「何がしたいか」部分に表があれば、優先して見ること(R2は荷積重量と荷卸重量を求め、結合して差引重量を求める表の説明があり、たいへん分かり易かった)。
- また、「何を求められているか」ベースで考えること。(R2はSQLの穴埋め部分と、前述の表を突き合わせれば回答できた。別途処理フローの詳細説明もあったが、これは必要に応じて参照するレベルであった)
⑤-2 改善後(論述)
- 現行のER図とスキーマ完成のあと、「現行業務の問題点とその改善策」や「改善後業務の内容」について論述する設問。(R3 PM1 Q1)
- 「設問を読み、仮説を立て、本文中のヒントを探し、どれを使うか選び、慎重に表現を選ぶ」が基本。
- 過去区分(ITストラテジスト、プロジェクトマネージャ、システムアーキテクト等)でもおなじみの問題。
- 注意点をいくつか。設問はしっかり確認。答えを絞り込む要素が記載されていることが多い。
- 仮説については、かなり単純であることも多い。まずは深く考えず直感かつシンプルで良い。
- 本文中のヒントは、読んでいる時「?」な箇所はマークしておく(否定表現(~できてない、~のみ~している)や、付け加え表現(なお~、このとき~))
- 複数のヒントからどれを使うかは、設問で「何を聞かれているか」に注意して選ぶ。もちろん、一般常識を組み合わせて回答することもあるが、基本は本文中からになる。(なぜなら、他の人もそのパターンはなかなか答えられないから)
- 最後の詰め。答えの表現は慎重に、キーワードは入れつつ、本文中の表現に合わせる。
SQLのコツまとめ
①基本戦略
- まず午後1対策として、論理設計以外の1問で何を選ぶかが課題。
- 直近3年の傾向と私の強みを踏まえ「(おそらく)問3のSQL多めの問題」が最有力候補。
- 約40分と限られた時間内で、本文の主旨(現状・課題・対策)を把握し、個々設問(SQL・結果行数・統計情報・各種定義の穴埋め)を解く必要がある。
- 即ち、短時間での読解力と実務力が問われるので、プロセスのパターン化と慣れが必要。
①(補足)直近の問題傾向
- 昨今の社会情勢として、ゴリゴリのDB作り込み能力はあまり求められない印象。
- なぜなら、日本の複雑な業務をそのままシステム化するとコスト高になるので、むしろクラウドパッケージにあわせ業務を簡素化する傾向があるから。
- むしろ「ユーザニーズをくみ取り、現行データを元にした、効率的なデータ分析基盤の提供」が重視されている印象。
- そこに求められるのはユーザニーズの読解力と、基礎的な実務知識。(応用的な知識は、業務内容に応じて深堀)。
- そして、試験問題の傾向も、これに即したものになっていく認識。(直近3年のテーマは全てこれ)
- ようは、直近3年のSQL多め問題をベースにパターン化した回答プロセスと、実務経験(私の場合は他試験区分の長文読解も含む)による読解力がコアスキルになる。
- そのうえで、SQLおよび物理設計の基礎知識(後述)を過去問から抑えておけば、かなり対応力は高まると認識。
②回答プロセスと注意点(全体)
- タイトル・見出し・小見出しに線を引き、その下1~2行に目を通し、「構造」把握
- 大きな構造ごとに長く横線で区切りブロック化する。これで長文がぐっと読みやすくなる。
- 設問に丁寧に線を引き、システム表現に焦らず、ユーザーニーズ(何がしたいか)に着目し、表や図も注意し、本文と設問の紐づけを行う。
- 本文、設問、(あればRDBMS仕様)、パズル要素の4つをベースに、順に回答していく。
- (注意)取れるものを取るため、難しいところは深入りしすぎない。
- (注意)ただし何らか答えは書く。部分点がもらえるかもしれないため
- (注意)繰り返しだが設問に注意。制約であり回答を絞り込む条件でもある
③回答プロセスと注意点(個々設問)
- 本文⇒かならずSQLで「したいこと」がある。そこを探す。
- 設問⇒埋めるのは字句か、数値か?回答の制約になるので、線を引いて丁寧に読む。
- パズル⇒既に埋まっている箇所は最大のヒント。
- 知識⇒三好先生のテキスト第1章(SQL)で抑えた知識を適用。
- (読解のコツ)分解⇒実務でSQLを見るときと同様、select部分、group by部分、入れ子表現なら内側…と少しづつ解きほぐして理解する。
- (読解のコツ)具体(図示)⇒少しでも?と思ったら、悩む前に図示する。結果として早い。とくに結合のときなど。
- (回答時の注意)AS⇒列名をかくときは、AS名.にすること(ただし、表が1つでASを使ってない場合は不要)
- (回答時の注意)シングルコーテーション⇒値をかくときつけているか?(基本は本文にあわせて忠実に)
④(参考)問題分析(R3 問3)
- まずR3 問3は「テーブルの移行およびSQLの設計」。”移行”とあるが物理知識は不要。”SQLの設計”とある通りSQL中心になる。
- Q1(1)前半は結果行数の計算問題。「表の行数÷where句条件の列値=結果行数」となる。表の行数は160万行と与えられており、空欄イは「沿線が○○線(列値400)、かつ設備にエアコン(列値2)とオートロック(列値2)がある」なので、160万÷400÷2÷2=1000となる。なおSQL3は結果行数400と埋まっているが、これは沿線ごとgroup byして物件数を集計するSQLなので、400の沿線ごと計算結果が出ているだけ。結果行数と、演算結果(値そのもの)を混同しないよう注意。
- Q1(1)後半は「まず、物件総数を求めてwith句でtemp表内のtotal列(1行1列)として用意し、次にtotalを物件表にcross joinで結合し、最後に沿線でgroup byしてcount(*)/totalする」一連の部分穴埋め。こう書くと難しいが、「”沿線ごと”なのでgroup byのあとは”沿線”だな」「”沿線ごとに集計した物件数”は、count(*)だな」「”全物件数”はtotalだな」と、一つ一つの日本語に分解して穴埋めすればそこまで難しくない。(今回は無かったが、既に埋まっているヒントがあればなお良い)
- Q1(2)は設備数を連関エンティティで切り出す案の長所。今回は「本文中の”課題”を探す⇒対策A,Bで対処可能か見る⇒案Bしかできないことを捉え、本文中の表現を用いて論述する」。
- Q1(3)前半はテーブルの移行に伴うSQL。本文読解に加え、「insert into 表名(列名,…)のあとにselectをunionで繋げていく構文知識」が必要。「selectが続いたらunionを疑う、unionはallをつけるか常に考える」は抑えたい。
- Q1(4)は統計情報の穴埋め問題。統計情報は、列値(ユニークな値)を本文から読み取る力が求められる。
- Q2(1)は移行後の表で、移行前の表と同じ結果を求めるSQLの問題。一部情報を別表に切り出したのでjoinが多用される。
- Q2(2)はdistinctを用いる理由で、これは「SQLで行っていること」のイメージが湧けば容易。
- Q2(3)は移行前の表から削除した情報を、ビューとして残すための問題。
- 問題全体を振り返ると、「設備の有無を横持ちすると大変なので、別表に切り出す」という「やりたいこと」を正しく理解したうえで、「データ分析(selectやjoin)」「移行(insert)」「ビュー作成」など個々実務を解く問題。
⑤(補足)物理設計の基礎知識
- 優先度が高いのは、パフォーマンスに係るもの。データ分析は鮮度と速度が命なので。
- まず、索引(性能)。索引はSQL構文を変えずに性能を上げるのでコスパが良い。索引の種類、SQL処理時間計算、統計情報計算、アンチパターン(統計情報が古いままで表探索になってしまう等)は抑えたい。
- 次に、同時実行処理。基本的には複数トランザクションを並列して動かすことになる。同時実行制御の種類、アンチパターン(デッドロックの起きるパタンと対策)は抑えたい。
- 次に、(性能向上を主目的とした)クラスタリング。分散キーの設定、アンチパターン(分散したのに一つのクラスタに集中、ログファイルがボトルネックになる…など)は抑えたい。
- 同時に優先度が高いのは、テーブル定義と制約に係るもの。ユーザニースの正しいくみ取り力が試されるので。各種制約、参照制約、トリガ等は抑えたい。
- なお、それ以外で抑えておきたいのはセキュリティ。これは、試験対策と社会情勢のため。まず試験対策として、H28年午後1は設問1が論理設計・設問2がバックアップ・設問3がセキュリティだったので、SQL優先ならセキュリティを抑える必要があった。次に社会情勢として、昨今では情報漏えいが注目テーマである。
基礎理論のコツまとめ
①基本戦略
- 午後1対策として、基礎理論を解けるようにしておくと非常に良い。
- なぜなら、まず出題される可能性が高いため。直近ではH29まで出題されており、H30,H31,R2に無かったあとR3に復活した。
- (つまり過去は頻出であった。かつ、センスの良いテーブル設計は実務上きわめて重要であり、その思考の補助線とも言える基礎理論はIPAとしては”できて当然”と考えていると思われる)
- 次に、そこそこ配分が大きいため。例えばR3 PM1 Q1なら回答欄の4割近く、H29 PM1 Q1なら回答欄の3割近くを占め、15~20点くらいの可能性も。
- (PM1は数点の差で落ちるケースが多いので、10点以上の配点を取れるか、取れないかは大事)
- 一方、回答プロセスを覚えれば得点しやすいため。
②回答プロセス
- (1)まず、設問を見て、基礎理論の問題かどうか判別する。
- これは、設問の表現が特徴的なので即時。(「候補キーを全て答えよ」「部分関数従属、推移関数従属の有無と、有る場合の具体例をそれぞれ1つ答えよ」「第何正規形が答えよ。第三正規形まで分解せよ」がパターン表現)
- (2)次に、もし基礎理論の場合、本文を見てヒント箇所を探す。
- 主に「本文中(見出し部とそれ以外)」「スキーマ」「属性の説明表」となる。記述箇所がある程度パターン化しているので、すぐアテを付けたい。
- なお、本文中の「○○とは~」という表を示す表現が、ヒントになることもあるので抑えておく。(例えば、R3は冒頭に「加盟企業は~」と書いてあるのに、スキーマを見るとこの表が無い。とても怪しい。これは結果として、”加盟企業商品”を分離して”加盟企業”を作るべきというヒントであった。)
- (3)次に、ヒント箇所から関数従属性を考える。以下a~dの手順となる。
- a,一意性表現の読み取り。たとえば「一意」、「識別する」、「一つに定まる」など。たとえば「施設はいずれか一つのエリアに属する」は「一つに定まる」の変形であり、注意。
- また、「同じ○○を登録できない」「○○は重複しない」など裏返し表現にも要注意。
- b,常識による仮説。大事なのは「テーブルは集合(意味のあるまとまり)かつ関数(一意に決まる)である」ということ。つまり表名や、スキーマの中身が、問題文そのままだと”ごった煮”に見えるはず。その違和感を元に、”表がどう作られるか”,”何のための表か”に着目しながら、切り出せる部分集合を考える。
- この”違和感”(本来ならこうあるべき)はとても大事。究極、これがあれば一意性表現を多少見落としても、分離後の正しいスキーマの予測がつくから。R3からは一意性表現が少なくなり、常識に基づき予測する部分が増えたので、恐らく今後もこの傾向になると予測。
- c,記述による検証。上記bの仮説について、本文中の記述や状況などから確認をしていく。
- d,逆パターンの確認。「表α→表βのとき、表α←表βの関係もないか?」と一つ一つ検証すること。これを漏らすと回答を大きく誤るので注意。
- (4)次に、候補キーを全て洗い出す。手順(3)で明らかにした関数従属性から図を書き、候補キーは「一意かつミニマム(すべての属性を決められる、最小の組み合わせ)」であることをふまえ、関数従属性の始点(→)を一つ一つ検証する。また、一つ候補キーが見つかったら、「この候補キーは他の何かで代替できないか?」を確認するのもポイント。
- (5)次に、部分関数従属および推移関数従属の有無と、具体例を答える。いずれも代表例でOKなことと、推移関数従属は「主キー→非キー→非キー」と書かねばならないことに注意。
- (6)最後に、第何正規形か答え、第三正規形まで分離する。
- まず正規形についてはうっかりミスをなくすこと。例えば第二正規形は「部分関数従属がない」ものだから、もし部分関数従属があるなら、それは第一正規形になる。
- 次に分離について、表名は悩むくらいなら主キー名そのものにする、という手もあるので覚えておくこと。
- また、主キーを示す実下線と、外部キーを示す点下線も引くこと。さらに、分離した表どうしをつなぐ属性以外に、元々あったほかの表とつなぐ外部キーも点下線を引くことに注意。(これは、他の設問でER図とスキーマを埋めていれば、気づきやすいが、念のため)
③過去問具体例(R3)
- 手順(1)設問。上述のテンプレな設問文なので、基礎理論問題だと確定。
- 手順(2)本文。「本文中の見出し”加盟企業商品”」および「スキーマ”加盟企業商品”」がヒント箇所だと分かる。また、「加盟企業とは~」や「横断分析用商品情報は~」などの表現もあるので抑えておく。
- 手順(3)関数従属性。まずa.一意性表現について。
- 「加盟企業商品は、加盟企業コードと加盟企業商品コードで識別する」とある。これにより、{加盟企業コード、加盟企業商品コード}→{それ以外の属性}が確定する。
- 次に「横断分析用商品コードと横断分析用商品名を設定し、横断分析用商品コードで識別する」とある。これにより、「横断分析用商品コード→横断分析用商品名」が確定する。
- これ以外に、一意性に関する記述はなさそう。
- 次にb.常識による推論について。
- まず”加盟企業商品”という表名と、”企業名”と”商品名”を併せ持っているスキーマの中身に着目。普通は”企業”表と”商品”表に分けるはずと考える。
- そこで、そもそもこの表がどのように作られるかを本文中から見て見る。すると、「加盟企業は、商品を登録するときに、当該加盟企業の商品コード、商品名、JANコードを登録する」とある。
- つまりイメージとして、”企業”マスタと、”商品登録”トランザクションを生成する感じだろうか。となると、少なくとも”企業”に係る集合は切り出せそうだ。
- 次にc.記述による検証について。
- 本文中に「同じ加盟企業と複数回の契約をすることはない」とあるので、企業を切り出すことは確定となる。具体的には、「加盟企業コード→{企業名など、企業に関わりそうな属性}」だ。
- 最後にd.逆パターンの確認について。
- 「加盟企業商品名やJANコードは再利用されることがある」「横断分析用商品名は一意になるとは限らない」から、逆向きの矢印はなさそうと考えられる。(契約開始日や契約終了日は常識的に一意性がない)
- 手順(4)候補キー。上記で確認した関数従属性を図にすると、以下のようになる。
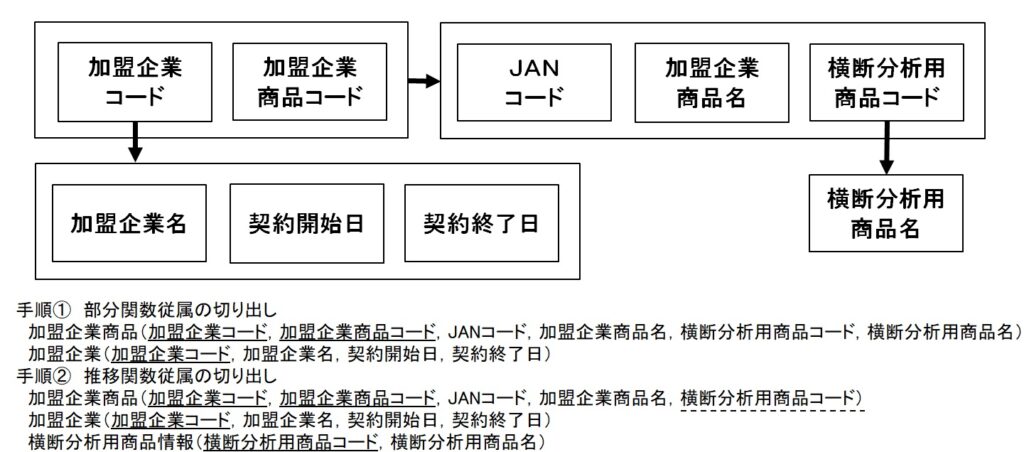
- 今回は{加盟企業コード、加盟企業商品コード}が主キーなので、候補キーにもなる。
- それ以外の要素は見当たらない。ただ、「この候補キーは他の何かで代替できないか?」と考える。
- すると、「加盟企業商品コードは、JANコードまたは横断分析用商品コードでも代替できるのでは?」となる。
- また、この設問のすぐ後に「候補キーのうち、主キーに成り得ないものを答えよ」とあるので、「候補キーが複数ある」「ただしそのうちの一つは、一意性は満たすが、非NULL制約は満たさないものだ」と予測できる。
- 今回は、それは横断分析用商品コードになる。なお、JANコードは「使いまわされることがある」とあり一意性を満たさないので、候補キーには成り得ない。
- 以上から、候補キーは{加盟企業コード、加盟企業商品コード}および{加盟企業コード、横断分析用商品コード}となる。
- 手順(5)部分関数従属および推移関数従属の有無と、具体例。これは上図を見て挙げる。部分関数従属は「加盟企業コード→加盟企業名」、推移関数従属は「{加盟企業コード、加盟企業商品コード}→横断分析用商品コード→横断分析用商品名」だ。
- 手順(6)第何正規形か答え、第三正規形まで分離。図のとおり部分関数従属を持つので、第一正規形とわかる。
- 分離の仕方は、図の下部参照。
④過去問具体例(H29)
- 手順(1)設問上述のテンプレな設問文なので、基礎理論問題だと確定。
- 手順(2)本文。「本文中の見出し”コミュニケーション機能”」および「スキーマ”電子会議投稿”」および「主な属性とその意味・制約」の3つがヒント箇所だと分かる。
- また、「電子会議とは~」、「投稿とは~」、「分野とは~」などの表現もあるので抑えておく。
- 手順(3)関数従属性。まずa.一意性表現について。
- 「電子会議番号は、電子会議を一意に識別する番号」とある。これにより、「電子会議番号→{電子会議に係る属性}」が確定。
- 「投稿番号は、電子会議番号との組み合わせで投稿を一意に識別する番号」とある。これにより{電子会議番号,投稿番号}→{投稿に係る属性}が確定。
- 「一つの分野内で表示順が重複することはない」とある。これはつまり、{分野番号,表示順}の組み合わせが一意ということ。そして、その組み合わせが導くのは本文から”電子会議”、つまり電子会議番号だと分かる。以上により「{分野番号,表示順}→電子会議番号」が確定。
- 次にb.常識による推論およびc.記述による検証について。
- まず”電子会議投稿”という表名と、”議題”と”投稿本文”を併せ持っているスキーマの中身に着目。普通は”電子会議”表と”投稿”表に分けるはずと考える。ただ今回は、すでに投稿に係る属性を切り出す関数従属性が表現から導かれているので、問題なさそうと判断する。
- 最後にd.逆パターンの確認について。常識的に考えて、議題や投稿本文が一意とは思えないので、逆は無いと判断する。
- 手順(4)候補キー。上記で確認した関数従属性を図にすると、以下のようになる。
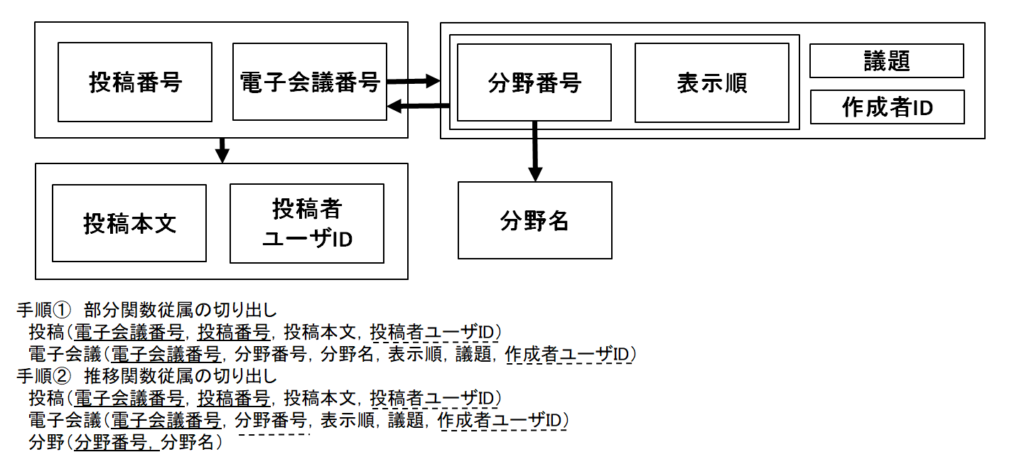
- 今回は{電子会議番号,投稿番号}がまず候補キーになりそうとわかる。
- 次に「この候補キーは他の何かで代替できないか?」と考える。
- すると、「電子会議番号は、{分野番号,表示順}でも代替できるのでは?」となる。(先ほど見た一意性表現により)
- 以上から、候補キーは{電子会議番号,投稿番号}および{分野番号,表示順,投稿番号}となる。
- 手順(5)部分関数従属および推移関数従属の有無と、具体例。これは上図を見て挙げる。部分関数従属は「電子会議番号→議題」、推移関数従属は「電子会議番号→分野番号→分野名」だ。
- 手順(6)第何正規形か答え、第三正規形まで分離。図のとおり部分関数従属を持つので、第一正規形とわかる。
- 分離の仕方は、図の下部参照。ユーザIDも外部キーなので下線を引いている点に注意。
⑤過去問具体例(H28)
- 手順(1)設問上述のテンプレな設問文なので、基礎理論問題だと確定。
- 手順(2)本文。「本文中の見出し”webサイトの概要”」および「スキーマ”周辺施設”」および「主な属性とその意味・制約」の3つがヒント箇所だと分かる。
- また、「設備とは~」、「カテゴリとは~」などの表現もあるので抑えておく。
- なおスキーマは「周辺施設(カテゴリコード、カテゴリ名、施設ID、施設エリアコード、施設名、駐車場ID、所要時間、施設経度、施設緯度)」とある。
- 手順(3)関数従属性。まずa.一意性表現について。
- 属性表に「カテゴリコードはカテゴリを一意に識別するコード」とあるので、カテゴリコード→カテゴリ名は確定。
- 属性表に「施設IDは施設を一意に識別する文字列」とあるので、施設ID→施設名は確定。
- 属性表に「経度および緯度を組み合わせた位置上に、駐車場または施設が複数存在することはない」とあるので、{施設緯度、施設経度}→施設IDは確定。
- 本文に「施設はいずれか一つのエリアに属する」とあるので、施設ID→施設エリアコードは確定。
- 本文に「施設はいずれか一つのカテゴリに属する」とあるので、施設ID→カテゴリコードは確定。
- 次にb.常識による推論およびc.記述による検証について。
- 属性表に「所要時間とは、駐車場から施設までの移動に要する時間」とある。また、本文中に「駐車場と施設の多対多関係」を匂わす表現があるので、駐車場IDと施設IDを持った連関エンティティを使うと予測できる。
- 最後にd.逆パターンの確認について。常識的に考えて、名称系が一意とは思えないので、逆は無いと判断する。
- 手順(4)候補キー。上記で確認した関数従属性を図にすると、以下のようになる。
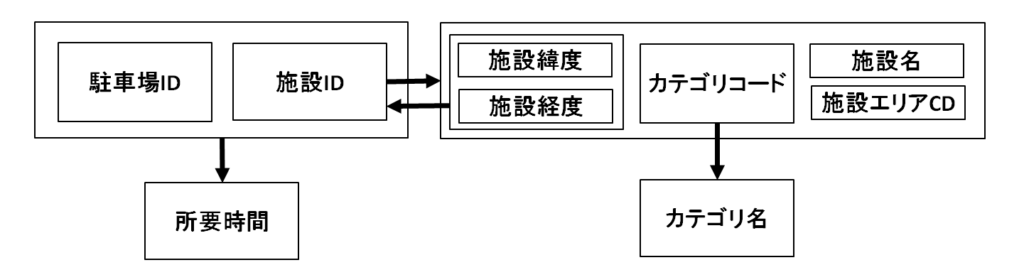
- これらから、候補キーは{駐車場ID,施設ID}および{駐車場ID,施設緯度,施設経度}とわかる。(後者は施設IDの入れ替え)
- 手順(5)部分関数従属および推移関数従属の有無と、具体例。これは上図を見て挙げる。部分関数従属の例は「施設ID→施設名」、推移関数従属の例は「施設ID→カテゴリコード→カテゴリ名」とわかる。
- 手順(6)第何正規形か答え、第三正規形まで分離。図のとおり部分関数従属を持つので、第一正規形とわかる。
- また、正規化後は以下になる。
- ①周辺施設(駐車場ID(主・外)、施設ID(主・外)、所要時間)※連関エンティティ
- ②施設(施設ID(主)、カテゴリコード(外)、施設エリアコード(外)、施設名、施設経度、施設緯度)
- ③カテゴリ(カテゴリコード(主)、カテゴリ名)
⑥過去問具体例(H25 PM1 Q2)
- 本文の表現は「期間、回数、曜日の組み合わせは、継続パターンコードで識別される。また、それによって継続割引率は異なる」という記述のみ。
- 一見すると「継続パターンコード→{期間、回数、曜日}→継続割引率」だが、「継続パターンコード←{期間、回数、曜日}」も成り立っている点に注意。いわゆるサロゲートキー的なものだろう。
- この場合、候補キー↔候補キー→非キーなので、部分関数従属も推移関数従属(主キー→非キー→非キー)もない、第三正規形になる。
⑦過去問具体例(H26 PM1 Q1)
- 本問は、関数従属性を示す図が最初から用意されていた。
- よって候補キーの洗い出しから行えばよく、きわめて簡単なケース。
参考資料
- 2022年度版 ALL IN ONE パーフェクトマスター データベーススペシャリスト/TAC
- データベーススペシャリスト2022年版/ITのプロ46 三好康之/翔泳社
- 集中演習 SQL入門/木田和廣/株式会社インプレス
- おうちで学べるデータベースのきほん/ミック、木村 明治/翔泳社

コメント